Cybersecurity Top Trends 2026–2028: The New Control Planes — Trust, Identity, Autonomy, and the AI Infrastructure Perimeter

The question security leaders are quietly getting asked—by boards, by audit committees, and increasingly by their own teams—is not “Are we secure?” It’s more specific, and more revealing:
“How do we know what’s real, who (or what) is acting, and what they’re allowed to do—at machine speed?”
That question exists because three shifts are converging at once.
First: trust is no longer ambient. Synthetic content is now good enough—and cheap enough—that enterprises are losing the shared reality they used to rely on. A voice message that sounds like the CFO, a screenshot that looks like an internal console, a “policy update” written in the company’s tone, a convincing outage narrative posted externally during an incident—these aren’t edge cases. They are becoming routine tactics. The result isn’t just fraud; it’s operational confusion, delayed response, reputational damage, and legal exposure.
Second: identity has become the dominant intrusion path. Many successful attacks now involve little or no malware. Adversaries steal sessions and tokens, abuse OAuth grants, persist through authorized apps, and move laterally through SaaS integrations and non-human identities that were never governed like humans. This is why “we had MFA” increasingly fails as an explanation after the fact: modern compromise is often permission- and session-based, not password-based.
Third: autonomy changes the blast radius. As agents move from pilots into production, the most consequential security failures won’t be limited to data exposure. They will be unauthorized actions—an agent installing a tool, changing a configuration, approving a workflow, sending a message, or triggering a financial process—because it had access, because it was tricked, or because its context was poisoned. In this world, the perimeter is not the model. It’s the AI infrastructure around the model: prompts and policies, retrieval and context, vector and graph stores, orchestrators and tool routers, memory/state, output handling, and runtime boundaries.
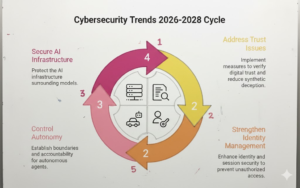
That’s why the trends for 2026–2028 cluster around new control planes—areas where control must be engineered, continuously verified, and auditable:
- Digital trust, fraud, and provenance to stabilize reality and reduce synthetic deception as an attack multiplier.
- LLM/GenAI application security and model exposure to handle prompt injection, unsafe outputs, and prompt/policy leakage as mainstream exploit classes.
- AI infrastructure security to secure context supply chains, retrieval authorization, ingestion pipelines, vector/graph layers, and orchestration integrity.
- Agentic autonomy and workflow integrity to prevent agent sprawl, control excessive agency, establish agent identity/accountability, and protect persistent memory.
- Shadow GenAI, supply chain, malware delivery, and AI compute monetization to close unmanaged exfiltration paths and adapt to AI-accelerated compromise and cost-based attacks.
- Expanded perimeter and hard deadlines including identity-first intrusion (tokens > passwords), SaaS integration abuse, machine-speed ops arms races, post-quantum migration urgency, and new network surfaces beyond terrestrial assumptions.
The goal of this article is practical: help leaders decide what must be built into architecture and operating model—not just bought as another tool—so the organization can keep moving fast without losing control of trust, identity, and autonomy.
Trend #1: Trust Collapse from Synthetic Content — Rebuilding “Shared Reality” Inside the Enterprise
From 2026 through 2028, one of the most expensive security failures won’t start with malware or a zero-day. It will start with something more basic: teams no longer agreeing on what’s real.
Synthetic voice, video, documents, screenshots, and “official-looking” messages are already good enough to move money, trigger workflow changes, and destabilize incident response. The Arup deepfake case—where criminals used AI-generated video identities to persuade an employee to transfer $25M—is a clear marker that this is operational, not theoretical (see coverage from the Financial Times and additional context from the World Economic Forum).
The winners will treat trust as an engineered control plane: verifiable channels, cryptographic integrity, provenance metadata, and tamper-evident records—not “training and hoping people spot fakes.”
Article content
The shift is from “detect fake media” to prove authenticity and integrity across enterprise communications and evidence—fast enough to act under pressure.
Three forces converge here:
1) Synthetic deception becomes an operational weapon, not just a fraud tactic Deepfakes are no longer limited to “CEO fraud” emails. They show up as video calls, audio messages, incident updates, and internal artifacts that look like legitimate operational evidence. The World Economic Forum’s cyber outlook explicitly frames the landscape as being intensified by emerging technologies and evolving criminal capability, with deepfakes contributing to the trust problem (WEF Global Cybersecurity Outlook 2025).
2) Incident response depends on shared reality—and attackers know it During outages or breaches, organizations often operate on screenshots, chat messages, and rapid approvals. Synthetic artifacts create confusion, trigger unsafe actions, and slow containment. The enterprise risk is not only direct loss; it’s delayed decisions and misdirected response when “facts” can be cheaply fabricated.
3) Provenance and authenticity standards move from media to enterprise-grade controls This isn’t only about watermarking or detection accuracy. The practical path is provenance: signed, tamper-evident assertions about who created something, when, how it changed, and whether it was AI-assisted. NIST’s guidance on reducing risks from synthetic content lays out technical approaches including authentication/provenance, labeling, and detection as complementary controls (NIST AI 100-4 PDF; NIST publication page). On standardization, the clearest anchor is C2PA, which specifies cryptographically signed, tamper-evident manifests attached to content (C2PA home; C2PA specification).
Business impact
- Fewer high-trust workflow losses (payments, vendor changes, payroll, customer support escalations) because approvals require verifiable integrity, not persuasive media.
- Faster incident response because teams can re-establish known-good channels and trusted evidence quickly.
- Lower legal and reputational exposure with tamper-evident records and defensible chains of custody.
- More reliable AI adoption because provenance practices extend naturally to AI outputs and internal artifacts (not just external media).
CXO CTAs
- Define “known-good channels” for critical actions: pre-agreed verification paths for payments, vendor banking changes, identity recovery, and incident command—no exceptions under stress.
- Implement signed approvals for high-risk workflows: cryptographic signing for sensitive approvals and change workflows; make repudiation difficult and audit reconstruction easy.
- Adopt provenance as a standard, not a project: start with executive communications + incident updates + high-risk workflow artifacts; expand to AI outputs and internal evidence over time using standards like C2PA.
- Treat synthetic-content risk as an IR scenario: run “trust failure” drills where fake artifacts appear mid-incident and the goal is to restore shared reality fast.
- Stop relying on detection alone: detection helps, but the durable strategy is authenticity + integrity + provenance, supported by process design and auditability (see NIST’s synthetic content risk guidance).
Trend #2: Deepfake-Enabled Impersonation Becomes a Default Fraud Vector — Hardening “High-Trust” Workflows
From 2026 through 2028, the fastest-growing fraud channel in many enterprises won’t be phishing email—it will be impersonation that feels real: a voice note that matches the CEO, a video call that looks like a supplier contact, a support interaction that convincingly mimics an employee under pressure.
This isn’t a niche threat anymore. Law enforcement warnings now explicitly describe campaigns using AI-generated voice messages and malicious messaging to build rapport and push targets onto alternate channels—because the goal isn’t just to trick someone, it’s to move the victim into a controllable conversation where verification is weakest. (Federal Bureau of Investigation)
The winners will stop treating this as an “awareness problem” and treat it as a business-control redesign problem: stronger verification for high-trust workflows, hard rules for channel switching, and identity proofing that assumes voice/video can be forged.
Article content
The shift is from “spot the fake” to make fraud expensive—by redesigning workflows so persuasion alone can’t authorize money movement, access recovery, or sensitive changes.
Three forces converge here:
1) Deepfakes collapse trust in voice and video—especially in support and approvals Attackers no longer need perfect deepfakes; they need plausible ones paired with urgency and context. The FBI has warned that criminals are leveraging AI to craft highly convincing voice/video messages for fraud schemes against businesses and individuals. (Federal Bureau of Investigation) In practice, the most vulnerable surface is often the human override path: helpdesk resets, vendor change requests, payroll changes, “urgent” executive approvals.
2) The “high-trust workflow” becomes the primary target (not the endpoint) Impersonation works best where organizations rely on speed, relationships, and informal verification:
- vendor bank detail changes
- payment approvals and treasury operations
- HR changes (salary, direct deposit, offboarding)
- customer support and account recovery This is why deepfake fraud scales: it targets process weaknesses, not technical ones. Public reporting on major corporate deepfake fraud illustrates that these attacks are already operationally effective. (European Parliament)
3) Verification must move from static checks to continuous, risk-based proofing The emerging pattern is “trust tightening only when harm is possible.” That means escalating verification when the request is high-risk, when channel switching occurs, when the caller pushes urgency, or when behavior deviates from baseline. Recent Microsoft security analysis describes how AI-powered deception is accelerating fraud and the need for countermeasures across the lifecycle of scams. (Microsoft) Microsoft’s January 2026 guidance on “deepfake hiring” also highlights the reality of support/helpdesk fraud and points to stronger authentication patterns (e.g., verified credentials) rather than knowledge-based questions. (TECHCOMMUNITY.MICROSOFT.COM)
Business impact
- Lower fraud losses and fewer “authorized but fraudulent” transactions because high-risk actions require stronger proof than voice/video.
- Reduced account takeover via support and recovery (often the soft underbelly of strong MFA).
- Faster investigations with better evidence trails (who requested, what channel, what verification happened, what policy was applied).
- Higher confidence to scale automation/agents because human approval steps are also hardened—not just APIs.
CXO CTAs
- Redesign high-trust workflows, not just security controls: map every path that can move money, change vendor details, reset credentials, or override policy—and require stronger verification for each.
- Implement “channel switching” rules: if someone requests moving from email to WhatsApp/Signal/Teams/phone mid-process, treat it as a risk event requiring step-up verification. (FBI guidance on campaigns pushing victims to alternate encrypted apps is a useful warning signal.) (Federal Bureau of Investigation)
- Harden helpdesk and recovery as tier-0 controls: eliminate knowledge-based questions where possible; adopt stronger proofing and auditable recovery flows. (TECHCOMMUNITY.MICROSOFT.COM)
- Introduce cryptographic approvals for high-risk changes: signing-based approval trails for vendor bank changes, payroll changes, privileged access grants, and sensitive configuration updates.
- Run “deepfake-in-the-loop” exercises quarterly: simulate voice/video impersonation during payment approvals and incident response—measure time-to-verify, time-to-stop, and policy adherence (don’t just test detection). (Microsoft)
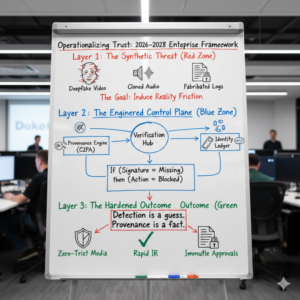
Trend #3: Enterprise Mis/Disinformation Becomes a Security Threat — Defending Decision Integrity During Incidents
From 2026 through 2028, “misinformation” stops being something the comms team worries about after a crisis and becomes something the security team must plan for during the crisis.
The modern playbook is simple: pair intrusion with narrative manipulation. While defenders are busy triaging alerts, adversaries (and opportunistic actors) seed false outage explanations, fake executive directives, spoofed screenshots, and counterfeit “fix instructions” that derail response, delay containment, or trigger unsafe actions. This is not just about public perception—it’s about operational control: whoever controls the story often controls the tempo of the incident.
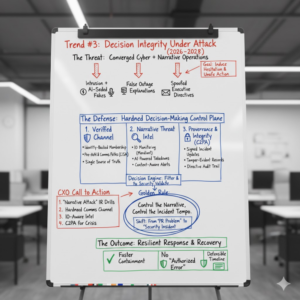
WEF’s Global Risks view reinforces why this is becoming systemic: misinformation/disinformation is ranked among the top near-term global risks, and cyber insecurity remains high on the same horizon—meaning enterprises should assume these risks will increasingly collide in real events (see the WEF Global Risks Report 2026 digest and the full WEF Global Risks Report 2026 PDF).
Article content
The shift is from “manage communications” to protect decision-making and response execution—because mis/disinformation now directly impacts how fast you contain, how cleanly you recover, and how much damage you take.
Three forces converge here:
1) Cyber + influence operations are converging in the real world Nation-state and aligned actors increasingly blend technical compromise with influence and narrative shaping. Microsoft’s reporting explicitly discusses how threat actors combine cyber activity with influence operations, and how these campaigns are becoming more scalable—especially as AI lowers the cost of producing synthetic content (see the Microsoft Digital Defense Report 2025 portal and the MDDR 2025 PDF). The implication for enterprises is direct: your incident may become a narrative battleground even if you’re not a public institution.
2) Narrative attacks work because they target the human control plane Mis/disinformation doesn’t need to be perfectly believable; it needs to be believable enough to introduce hesitation, parallel decision paths, or unsafe “fixes.” Common enterprise patterns include:
- fake “from the CIO/CISO” messages during an outage (“disable MFA,” “use this emergency login,” “run this script”)
- spoofed customer support interactions designed to force resets or override verification
- false “root cause” narratives that distract teams from containment priorities CISA’s incident playbooks reinforce that effective response depends on coordinated, repeatable processes and communications—exactly what narrative manipulation seeks to disrupt (see the CISA Federal Cybersecurity Incident & Vulnerability Response Playbooks PDF).
3) AI makes mis/disinformation industrial-scale and context-aware AI doesn’t just generate fake media; it generates tailored messages that match internal tone, org charts, and current events. Microsoft has reported on AI’s role in scaling influence and deception campaigns (see the MDDR links above), while Mandiant has published on how to interpret and operationalize intelligence on information operations as a distinct discipline alongside traditional threat intel (Google Cloud / Mandiant on information operations). The result: disinformation becomes faster, more targeted, and easier to coordinate with technical activity.
Business impact
- Slower containment and higher losses due to misdirected response, parallel command chains, and delayed decisions.
- Higher probability of “authorized error”: people take unsafe actions because the instruction looked legitimate under pressure.
- Increased reputational and regulatory exposure if false narratives spread faster than verified updates.
- More complex post-incident forensics because evidence, timelines, and “who said what” become disputed.
CXO CTAs
- Treat mis/disinformation as an incident scenario, not a PR problem: add “narrative attack” injects into tabletop exercises—fake screenshots, spoofed directives, and false root-cause memos—then measure decision latency and policy adherence. (Use the operational discipline in the CISA response playbooks as your baseline for what must remain stable under stress.)
- Establish a hardened incident command channel with identity-backed membership: one authoritative channel for directives and updates, with clear rules for verification and escalation.
- Pre-author “known-good” external communications paths: ensure customers, partners, and regulators know where verified updates will appear—then stick to it.
- Operationalize IO-aware threat intelligence: extend intel beyond malware/TTPs to include influence/narrative monitoring and takedown workflows (Mandiant’s framing is a practical starting point: information operations intelligence).
- Make provenance and integrity part of crisis operations: signed updates for high-impact announcements, tamper-evident records of incident directives, and strict controls over who can publish “official” artifacts (reinforced by the broader trust collapse controls discussed in Trend #1 and aligned with standards directions like C2PA).
Trend #4: Deepfake-Resistant Business Controls for High-Risk Workflows — Designing “Proof, Not Persuasion”
From 2026 through 2028, most organizations will discover a painful truth: their strongest security controls are routinely bypassed by their weakest business processes.
Deepfake-enabled fraud doesn’t need to defeat encryption or EDR. It needs to convince a human (or a rushed team) to approve a payment, change a vendor bank account, reset an account, or override a policy—usually through the same channels the business already trusts. The FBI’s business email compromise guidance has been consistent for years: verify payment changes and account updates using independent confirmation, not the same channel that initiated the request (FBI BEC guidance). In the AI era, that “verify independently” principle becomes non-negotiable because voice/video can be forged at scale.
The winners will move from “awareness and detection” to workflow design: dual control, verified channels, cryptographic approvals for the highest-risk actions, and incident exercises that assume deepfakes appear mid-stream.
Article content
The shift is from protecting systems to protecting decision points—because the highest-impact attacks now target business approvals and recovery paths.
Three forces converge here:
1) High-trust workflows are now the easiest way to move money or change truth Attackers concentrate on processes with speed pressure and social trust: payments, vendor banking changes, payroll updates, urgent procurement, customer support escalations, and identity recovery. Even classic BEC guidance from government agencies frames payment diversion as a primary risk, with recommended mitigations centered on verification and internal controls (see CISA’s long-running alert on BEC fraud patterns and response basics: CISA BEC alert). Deepfakes amplify that playbook by making the “trusted person” feel present.
2) “Out-of-band” is being redefined: email is increasingly not an independent channel A core lesson of the last decade is that if attackers control email or collaboration accounts, verification inside those channels is circular. NIST’s Digital Identity Guidelines updates reinforce this direction—for example, revisions to SP 800-63 explicitly discuss authenticator channels and session management, including tightening assumptions around out-of-band mechanisms (NIST SP 800-63-3 PDF). The practical implication for business workflows is clear: “verify by replying to the email” is not verification.
3) Controls must be “stress-proof,” not “policy-perfect” Under urgency, humans revert to the path of least resistance. That’s why controls like “call-back verification,” dual approvals, and enforced waiting periods matter: they are designed to hold under pressure. Microsoft’s Cyber Signals reporting on AI-powered deception makes the broader point that AI is accelerating scams and fraud, and emphasizes countermeasures that reduce the attacker’s ability to impersonate and pressure victims (Microsoft Cyber Signals Issue 9).
Business impact
- Material reduction in payment diversion and vendor fraud because the workflow requires independent proof, not persuasive conversation.
- Lower account takeover via helpdesk/recovery because resets require stronger verification and auditable steps.
- Faster investigations because high-risk changes produce reliable evidence trails (who approved, through which verified channel, with what policy applied).
- Better control over agentic automation because the same high-risk guardrails apply to “AI-initiated” actions, not just human requests.
CXO CTAs
- Map your “high-trust workflows” and treat them like tier-0 systems: payments, vendor banking, payroll, identity recovery, privileged access grants, incident command—then apply a minimum verification standard to each. Use the FBI’s pragmatic baseline—independent verification for payment changes—as the starting point (FBI BEC guidance).
- Enforce dual control for irreversible actions: separate “request,” “verify,” and “approve” roles so no single person can both update a payee and release funds (segregation-of-duties remains one of the most durable anti-fraud controls, reinforced in ACFE guidance on internal controls and authorization separation: ACFE article on internal controls and segregation).
- Adopt verified call-backs and known-good channels: require confirmation using pre-registered contact methods, not “whatever number is in the email.” Treat channel switching as a risk event (this is aligned with how government and industry describe BEC operational patterns and mitigations, e.g., CISA and FBI references above).
- Introduce cryptographic approvals for your highest-risk changes: for vendor bank changes, payroll changes, privileged access grants, and production configuration changes—make the approval trail tamper-evident and hard to repudiate (this also sets you up for later digital provenance controls).
- Test these controls under realistic pressure: run “deepfake + urgency” simulations in finance/AP and HR, not just phishing simulations. Your goal isn’t to “spot the fake”; it’s to ensure the process forces verification even when people are stressed (tie this to your incident response exercises and the broader fraud countermeasure framing in Microsoft Cyber Signals Issue 9).
Trend #5: Digital Provenance & Content Authenticity Becomes a Control Plane — Making Integrity Verifiable, Not Assumed
From 2026 through 2028, enterprises will stop treating authenticity as a “media problem” and start treating it as infrastructure. In a world where voice, video, documents, tickets, screenshots, and even “official” incident updates can be convincingly forged, the only durable answer is not better guessing—it’s verifiable integrity.
This is why digital provenance is now being framed as a top strategic technology trend: Gartner explicitly places “Digital Provenance” in its 2026 top strategic technology trends, positioning it as a trust and governance priority for the AI-powered enterprise (see Gartner’s 2026 trends list that includes Digital Provenance alongside AI security platforms and preemptive cybersecurity: Gartner Top Strategic Technology Trends for 2026; also the 2026 “Vanguard” framing here: Gartner technology trends FAQ).
The winners will build provenance the way they built identity: as a default mechanism that creates trustworthy, auditable evidence trails across high-risk communications and high-impact artifacts.
Article content
The shift is from “detect deepfakes” to prove origin, integrity, and chain-of-custody—across content, decisions, and eventually, AI outputs.
Three forces converge here:
1) Detection is necessary—but it is not sufficient As generative video improves, “deepfake detection” alone becomes brittle: it’s probabilistic, easy to evade, and often arrives too late. Even mainstream coverage has highlighted a hard operational truth: provenance metadata can be stripped or ignored by platforms, and no single technique solves the problem end-to-end (see the discussion of metadata stripping and the limits of provenance-only approaches in reporting like The Verge’s analysis of C2PA/Content Credentials adoption gaps: The Verge). That doesn’t make provenance irrelevant—it makes it foundational but incomplete: provenance must be combined with process controls, platform enforcement where possible, and “known-good channels” for high-stakes actions.
2) Standards and ecosystems are finally making provenance implementable The reason provenance is graduating from theory to control plane is standards maturity. C2PA’s specification defines “Content Credentials” as cryptographically bound provenance structures (manifest, claims, signatures) that can be embedded or stored externally and verified later (see the spec itself: C2PA Specification and the explainer: C2PA Explainer). Vendor ecosystems are moving too. Adobe has been explicitly positioning Content Credentials as enterprise-grade authenticity tooling and describing it as a way to produce transparent, verifiable creation records across workflows (see: Adobe on enterprise content authenticity).
3) Provenance expands beyond media to “enterprise truth” Enterprises will extend provenance from images and videos into the assets that drive operational decisions:
- high-risk approvals and workflow changes
- incident communications and status updates
- customer-facing messages that can trigger action
- audit evidence and investigation artifacts
- and—critically—AI outputs (what the system claimed, what it used, what changed, and when)
NIST’s synthetic content work reinforces the broader toolkit and points to authenticating content and tracking provenance as a key approach alongside labeling/watermarking and detection (see NIST’s overview page: NIST synthetic content risk overview and the full report: NIST AI 100-4 PDF). The practical takeaway is straightforward: provenance is what lets you move from “we think” to “we can prove.”
Business impact
- Reduced fraud and faster containment because high-stakes communications and approvals can be validated quickly.
- Higher confidence during incidents because “official updates” and command directives can be authenticated, reducing narrative interference.
- Stronger audit defensibility via tamper-evident chains of custody for evidence artifacts and decisions.
- Safer AI scale-out because provenance becomes the backbone for “why did it answer that?” and “what did it rely on?”—especially when outputs influence actions.
CXO CTAs
- Start where trust failure is most expensive: require authenticity controls for incident command updates, executive directives, and high-risk workflow approvals before you chase “provenance everywhere.”
- Standardize on verifiable provenance formats: adopt Content Credentials/C2PA for content workflows where relevant, and extend the pattern to enterprise artifacts that matter (C2PA gives a concrete, cryptographic model: C2PA Spec).
- Treat provenance as an evidence system, not a watermark: provenance must support investigations, audits, and dispute resolution—aligned to NIST’s framing that provenance/authentication is a core risk-reduction technique, not a nice-to-have (NIST AI 100-4).
- Design for “stripping” and “non-compliance”: assume metadata will be lost in some hops; compensate with process controls, signed approvals for critical workflows, and known-good channels (the “metadata stripping” reality is well documented in practice: The Verge).
- Make provenance operational, not performative: define who verifies, when verification is mandatory, and what happens when authenticity cannot be established (block, escalate, or quarantine).
Trend #6: Prompt Injection Becomes a Core Exploit Class — When “Words” Become a Control Surface
From 2026 through 2028, one of the most common entry points into AI-enabled systems won’t be a software bug in the classic sense. It will be instruction smuggling: attackers using carefully crafted text to make an LLM ignore policy, reveal sensitive data, or take actions it was never intended to take.
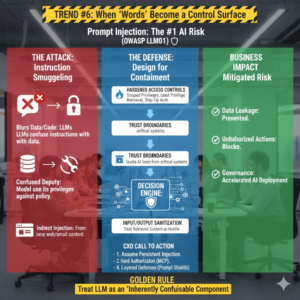
Prompt injection is now consistently framed as a top-tier risk in mainstream guidance. OWASP’s Top 10 for LLM Applications ranks Prompt Injection as the #1 risk (LLM01), signaling that the industry now treats it as a first-order security problem, not a novelty (OWASP Top 10 for LLM Applications; see also the 2025 LLM01 detail page: OWASP LLM01: Prompt Injection). NIST’s AI Risk Management Framework also calls out direct and indirect prompt injection as real attack modes with downstream consequences to interconnected systems (NIST AI RMF 1.0 PDF).
The winners will stop treating prompt injection like a content-moderation issue and start treating it like an application security and authorization problem: trust boundaries, scoped privileges, tool execution guardrails, and “safe by design” patterns that assume the model can be manipulated.
Article content
The shift is from “filter bad prompts” to design systems where prompt injection can’t easily translate into data exfiltration or unauthorized action.
Three forces converge here:
1) LLMs blur the line between instructions and data—so attackers exploit the ambiguity Traditional injection vulnerabilities were mitigated by separating code from data. LLMs don’t naturally enforce that separation; they predict outputs from combined context. That’s why the UK’s NCSC has warned that prompt injection is fundamentally different from SQL injection and may not be “fully solvable” in the traditional sense—pushing leaders toward impact reduction through system design rather than expecting perfect prevention (discussion summarized in coverage of NCSC’s warning: TechRadar).
2) Prompt injection becomes business-critical the moment the model can access data or tools A harmless chatbot that answers FAQs is one thing. A model connected to enterprise search, ticketing, email, code repositories, or administrative tools is another. The “confused deputy” pattern becomes the core risk: an attacker gets the model to use its privileges on their behalf. OWASP’s LLM01 framing explicitly includes bypassing intended behavior and safety measures, and the broader OWASP set links closely related flaws like Insecure Output Handling (which we’ll cover next) to real-world exploit chains (OWASP Top 10 for LLM Applications).
3) The exploit surface expands beyond chat: prompt injection targets the full AI app stack Prompt injection isn’t confined to “a user typing a malicious prompt.” Microsoft’s guidance on Model Context Protocol (MCP) discusses how indirect injection arises when malicious instructions are embedded in external content that tools retrieve—exactly the pattern that becomes dangerous when agents browse, ingest, and act (Microsoft: Protecting against indirect injection attacks in MCP). And the research landscape is accelerating: a January 2026 paper on prompt injection attacks against agentic coding assistants catalogues dozens of techniques including tool poisoning and cross-origin context poisoning, and argues many defenses still provide limited mitigation against adaptive attackers (arXiv: Prompt Injection Attacks on Agentic Coding Assistants, Jan 2026).
What enterprises get wrong (and why it fails)
- Treating it as a “jailbreak” problem: jailbreak detection helps, but injection often aims at data access and tool misuse, not policy-breaking content.
- Assuming system prompts are secret: system prompts and routing prompts leak in practice; operational security must assume adversaries can infer or extract policies over time (we’ll cover leakage as its own trend in #9).
- Over-trusting the model’s output: if the system accepts model output as “trusted,” injection turns into workflow injection immediately (Trend #8).
Business impact
- Data leakage through “helpful” retrieval: models reveal sensitive context they can access, especially when retrieval is over-broad.
- Unauthorized actions at scale: ticket closures, configuration changes, account actions, approvals—performed by the model under manipulated intent.
- Increased governance pressure: if you can’t show that injected instructions can’t trigger harmful actions, regulated deployments stall.
CXO CTAs
- Assume prompt injection is persistent and design for containment: treat the model as an “inherently confusable component” and limit what a compromised interaction can do (aligned with the NCSC-style warning posture reported here: TechRadar).
- Put hard authorization boundaries around tools and data: the model should never hold broad standing privileges; require scoped tokens, least privilege retrieval, and step-up approval for high-risk actions (Microsoft’s MCP guidance is practical here: MCP indirect injection mitigations).
- Treat retrieved content as hostile by default: sanitize, label, and constrain what content can influence action policies—especially when external browsing or email/doc ingestion is involved.
- Instrument and test injection continuously: run automated injection tests against real workflows, not toy prompts; validate that failures degrade safely (the 2026 agentic assistant attack catalog is a good reference for technique breadth: arXiv Jan 2026).
- Adopt layered defenses where they fit your stack: for example, Microsoft documents “Prompt Shields” for detecting user prompt injection and document-based attacks as part of Azure AI Content Safety (Microsoft Learn: Prompt Shields; and overview blog: Azure Prompt Shields).
Trend #7: Indirect Prompt Injection Dominates Real-World Attacks — When “Content” Becomes the Attack Vector
From 2026 through 2028, the most dangerous prompt injections won’t start in the chat box. They’ll start in the content your AI system reads—a web page, a PDF, an email, a ticket, a wiki page, a code comment, a vendor document—anything that can be retrieved, ingested, summarized, or used as context.
OWASP now explicitly describes indirect prompt injection as a core form of LLM01 (Prompt Injection): the attacker plants hidden instructions in external sources that the model later consumes, shifting the model’s behavior without direct access to the interface (OWASP LLM01: Prompt Injection). NIST’s AI RMF calls out the same pattern: adversaries inject prompts into data that’s likely to be retrieved by an LLM-integrated application, creating downstream consequences to interconnected systems (NIST AI RMF 1.0 PDF).
The winners will treat retrieved and ingested content as hostile by default and design retrieval, tool use, and action execution so that “reading a document” can’t quietly become “doing an attacker’s work.”
Article content
The shift is from “protect the prompt” to protect the ingestion and retrieval surfaces—because indirect injection turns your knowledge base into an execution path.
Three forces converge here:
1) RAG and browsing turn untrusted text into privileged context As soon as assistants and agents retrieve documents to answer questions, the attack surface expands from “user input” to “everything the system can read.” Indirect injection works because the model doesn’t reliably distinguish instructions from information—so hidden directives embedded in documents can override intent once retrieved. A 2026 paper focused on “indirect prompt injection in the wild” frames this as an attack surface created specifically by retrieval from external corpora: hidden instructions planted in corpora hijack model behavior once retrieved (arXiv PDF: Overcoming the Retrieval Barrier—Indirect Prompt Injection in the Wild for LLM Systems, 2026).
2) “Content compromise becomes action compromise” when agents have tools Indirect injection becomes truly costly when the AI system can do more than summarize—when it can open tickets, send messages, modify configs, execute code, or call APIs. That’s where the “confused deputy” pattern becomes practical: the attacker doesn’t need access to the tool; they need access to the content that influences the tool-using model. Microsoft’s guidance on Model Context Protocol (MCP) is blunt about this: indirect injection arises when a model reads untrusted content (webpages, emails, docs) and follows instructions found there, and mitigations require layered controls beyond “better prompts” (Microsoft: Protecting against indirect prompt injection attacks in MCP). Microsoft’s MSRC also describes design choices that reduce risk, including fine-grained permissions and governance, because these attacks often exploit the application operating with the same access permissions as the user (MSRC: How Microsoft defends against indirect prompt injection attacks).
3) The attacker doesn’t need “LLM access”—they need a path into your corpora This is why indirect injection is operationally attractive: the adversary can plant instructions anywhere that later becomes retrievable—support tickets, issue descriptions, shared docs, customer emails, vendor PDFs, compromised web pages, or even internally editable knowledge bases. That shifts security ownership: it’s no longer only the AI team’s problem; it’s a content governance, retrieval authorization, and pipeline integrity problem. Even practical security community guidance now emphasizes that indirect injection is more subtle and often more serious because the attacker never touches the chat interface—they target the content the model will later read (Bugcrowd, Feb 2026).
What enterprises get wrong (and why it fails)
- “We’ll sanitize the prompt”: sanitizing user input doesn’t help if the malicious instruction arrives via retrieval.
- “We’ll just trust our internal wiki”: internal corpora are editable, compromised, or stale—treating them as trusted implicitly makes them a privileged attack surface.
- “We’ll block obvious jailbreak phrases”: indirect injection is often hidden (e.g., white text, metadata, or buried content) and doesn’t look like a jailbreak.
Business impact
- Silent data leakage: injected instructions can manipulate the model to reveal sensitive retrieved context or prompt it to “summarize” in a way that exposes secrets.
- Unauthorized workflow actions: injected instructions cause ticket closures, permission changes, or external messages that look legitimate because they were executed through a trusted agent.
- Integrity failures: the system’s behavior changes persistently because poisoned sources get repeatedly retrieved, creating recurring compromise patterns (especially in shared corpora).
CXO CTAs
- Treat retrieved content as hostile by default: apply “untrusted input” thinking to everything that can enter context—web, email, documents, tickets—consistent with OWASP’s framing of indirect injection as external-content-driven manipulation (OWASP LLM01).
- Enforce permissioned retrieval: retrieval must obey identity entitlements and least privilege; “the model can see it” must not imply “the user should see it.” NIST’s AI RMF explicitly flags indirect injection as a path into interconnected systems via retrieved data—so retrieval authorization is not optional (NIST AI RMF PDF).
- Separate “read” from “act”: make tool execution require explicit policy checks and step-up approvals for high-risk actions; don’t let retrieved text directly drive actions. Microsoft’s MCP guidance emphasizes layered defenses and specifically addresses indirect injection risks when tools are in play (Microsoft MCP guidance).
- Add context firebreaks: label, quarantine, or down-rank untrusted sources; block hidden-instruction patterns; and log “why this content entered context.” Microsoft documents “Prompt Shields” that include document attacks as a detection layer in Azure AI Content Safety (Microsoft Learn: Prompt Shields).
- Test indirect injection continuously: red-team your actual RAG corpora, browsing paths, and tool workflows. Use real techniques described in recent research on indirect injection in retrieved corpora (arXiv 2601.07072) and validate that failures degrade safely.
Trend #8: Insecure Output Handling Returns as a Top App Flaw — When Model Output Becomes an Injection Payload
From 2026 through 2028, many AI incidents won’t look like “the model said something wrong.” They’ll look like this: the model said something that got executed.
As GenAI moves from chat to workflows—tickets, emails, scripts, dashboards, approvals, automation steps—LLM output increasingly flows into downstream systems that were never designed to treat natural language as untrusted input. That’s exactly why OWASP elevates Insecure Output Handling as a top risk for LLM applications: if you don’t validate and sanitize outputs before passing them downstream, you can trigger classic vulnerabilities like XSS/CSRF in browsers or SSRF/RCE and privilege escalation in backend systems (OWASP Top 10 for LLM Apps and the specific risk write-up: OWASP LLM02: Insecure Output Handling).
The winners will treat LLM output like any other untrusted, attacker-influenced input: typed, constrained, validated, and sandboxed—especially when it crosses into tools, code, commands, tickets, and UI rendering.
Article content
The shift is from “the model generates text” to the model generates instructions that can land in execution surfaces—and output handling becomes the difference between “bad answer” and “breach.”
Three forces converge here:
1) LLM output is attacker-influenced by design If an attacker can influence the prompt (directly) or the retrieved context (indirectly), they can influence the output. That makes raw output dangerous when it’s treated as trusted. OWASP is explicit that insecure output handling is often chained with successful prompt injection—because prompt injection is how attackers shape the output, and insecure output handling is how that shaped output becomes exploit delivery (OWASP LLM02).
2) Every downstream destination is a different exploit surface The same model response might be:
- rendered inside a browser-based UI (XSS risk)
- embedded into an email or ticketing system (workflow injection / social amplification)
- written into a database or log (later rehydrated into dashboards and UIs)
- passed into an API call, script, or automation step (SSRF/RCE risk) OWASP’s definition calls out that passing unvalidated output downstream can lead to serious exploit outcomes, including code execution and data exposure (OWASP Top 10 for LLM Apps).
3) “Structured outputs” and agent tools make output handling an execution boundary In modern stacks, LLMs are used to generate JSON, SQL fragments, search filters, workflow actions, or tool parameters. If output parsing is lax—accepting arbitrary keys, URLs, file paths, commands, or templates—then the model becomes a convenient injection router. Microsoft’s security planning guidance for LLM apps calls out the risk directly: insufficient scrutiny of LLM output and unfiltered acceptance can lead to unintended code execution—explicitly framing “Insecure (Improper) Output Handling” as a threat to confidentiality (Microsoft Learn: Security planning for LLM-based applications).
What enterprises get wrong (and why it fails)
- “We only execute output we ask for.” If an attacker can influence the prompt/context, they can influence what the model chooses to output—especially in edge cases and tool-routing scenarios.
- “We’ll rely on prompt instructions like ‘don’t output code.’” Prompts aren’t enforcement. They are guidance that fails under adversarial conditions (as seen in prompt injection patterns already documented in Trend #6 and #7).
- “We’ll sanitize later.” Output is often copied into multiple systems; by the time it’s “sanitized,” it’s already executed or rendered somewhere else.
Business impact
- Browser-layer compromise when LLM output is rendered into portals, admin consoles, customer support tools, or internal dashboards without strict encoding and sanitization.
- Backend compromise or data exfiltration when output is passed into tools that fetch URLs, run commands, query systems, or interact with cloud APIs.
- High-frequency “near misses” that don’t show up as breaches, but create ongoing integrity and productivity drag as teams chase weird automation behavior.
CXO CTAs
- Treat LLM output as untrusted input everywhere it lands: if it’s rendered, encode/sanitize; if it’s executed, validate and constrain; if it’s stored, label and handle it as potentially attacker-influenced. OWASP’s framing makes this explicit—output handling is a security boundary, not a UI concern (OWASP LLM02).
- Require typed, schema-bound outputs for anything that drives tools or workflow actions: use strict JSON schemas, allowlists, and canonical parsers; reject outputs that don’t match expected structure.
- Separate “generate” from “execute” with policy gates: execution should require explicit authorization checks and (for high-risk actions) step-up approval—aligning with Microsoft’s guidance that unfiltered output acceptance can lead to unintended code execution (Microsoft security plan for LLM apps).
- Sandbox tool execution and constrain egress: prevent outputs from becoming arbitrary URLs, file paths, or commands; apply network egress controls and allowlisted destinations.
- Test output-handling chains, not just prompts: red-team the full “output → parser → tool → side effect” path; verify safe failure modes when outputs are malformed or adversarial.
Trend #9: Prompt/Policy Leakage Becomes Operational Security — When the “Rules” Themselves Become a Target
From 2026 through 2028, enterprises will learn (often the hard way) that system prompts, routing prompts, tool policies, and safety instructions are not just configuration—they are attack-relevant intellectual property and, in many cases, security-sensitive material.
Once an attacker can extract or infer your system prompt and policy scaffolding, they’re no longer guessing how your AI behaves. They have the operator manual: how to bypass guardrails, which tools exist, what the agent prioritizes, what it refuses, and—too often—what “hidden” connections or credentials were mistakenly embedded. OWASP now treats this as a distinct risk: System Prompt Leakage (LLM07), warning that prompts may unintentionally expose sensitive information and enable follow-on attacks (OWASP LLM07: System Prompt Leakage). Even Microsoft’s own guidance emphasizes that system messages help steer models but should be treated as just one layer—because they are not a security boundary or secure storage (Azure OpenAI: Safety system messages).
The winners will treat prompts and policies like production code: versioned, access-controlled, tested, monitored, and never used as a place to hide secrets.
Article content
The shift is from “keep prompts private” to assume prompts can leak and engineer systems that remain safe even when they do.
Three forces converge here:
1) Prompt artifacts become crown jewels because they encode business logic and security posture In enterprise deployments, system prompts often contain more than style guidance. They can encode:
- business rules (“how we approve refunds,” “how we handle customer disputes”)
- compliance logic (“what is allowed to be disclosed”)
- operational playbooks (“how to interpret incidents,” “what systems to query”)
- tool routing logic (“when to call which connector”) OWASP’s system prompt leakage risk highlights that discovering these instructions can reveal sensitive operational details and facilitate other attacks (OWASP LLM07).
2) Attackers don’t need the full prompt—partial leakage is enough to improve success rates Prompt leakage often happens incrementally: the model discloses fragments, policies can be reconstructed over multiple interactions, or hidden routing prompts are revealed via errors, debug outputs, or tool logs. In practice, even “harmless” leakage (e.g., the names of internal tools, exact refusal language, or hidden decision criteria) improves attacker efficiency in prompt injection and tool misuse. This is why guidance increasingly frames system prompts as probabilistic mitigations—not guarantees (Microsoft explicitly notes system prompts reduce likelihood but are only one layer, and broader defenses are required: Microsoft MSRC on indirect prompt injection defenses).
3) Prompt leakage becomes a security incident when prompts contain secrets or privileged structure The most avoidable failure mode is when teams embed credentials, internal endpoints, or privileged instructions directly into prompts (“use this API key,” “call this internal URL,” “here’s the admin procedure”). OWASP’s framing makes this explicit: system prompts may inadvertently contain sensitive information that was never intended to be discovered—and when discovered, it can be used to facilitate other attacks (OWASP LLM07). This is also why NIST’s AI Risk Management Framework stresses that prompt injection (direct and indirect) can have downstream consequences to interconnected systems—meaning “prompt artifacts” aren’t isolated; they interact with access and tooling in real environments (NIST AI RMF 1.0 PDF).
What enterprises get wrong (and why it fails)
- Treating the system prompt like a vault. It’s text passed to a probabilistic system; it’s not confidential storage. Microsoft’s “safety system messages” guidance explicitly positions system messages as one layer in a broader strategy—useful, but not a boundary (Azure OpenAI system message guidance).
- Assuming “users can’t see it” equals “attackers can’t infer it.” Over time, behavior reveals policy. Error cases and tool outputs often reveal more.
- Letting prompt and policy sprawl happen informally. Once teams copy prompts into docs, tickets, and chats, leakage becomes inevitable.
Business impact
- Higher success rate of prompt injection and indirect injection because attackers can tailor inputs to your exact guardrails and tool routing.
- Exposure of business logic and compliance rules that should not be public (pricing, eligibility, escalation paths, fraud controls).
- Security regression at scale: prompt changes become unreviewed “shadow releases,” creating inconsistent behavior across agents and environments.
- IP loss for proprietary agent workflows, routing prompts, and evaluation harnesses—especially in competitive sectors.
CXO CTAs
- Create a “PromptOps” discipline: treat system prompts, routing prompts, and policies as production assets—version control, code review, approvals, and rollback. If prompts steer decisions or actions, changes must be governed like software releases.
- Ban secrets in prompts—enforce it: secrets (keys, tokens, credentials, internal admin steps) must live in secure stores and be accessed via scoped runtime mechanisms, never embedded as plain text in instructions (aligned with the OWASP warning that prompts may expose sensitive information: OWASP LLM07).
- Assume leakage and design for safe failure: if a prompt leaks, the system should still be safe because tool permissions, retrieval authorization, and action gating enforce boundaries (consistent with Microsoft’s guidance that prompts are probabilistic mitigations and must be layered: Microsoft MSRC).
- Instrument “prompt artifact exposure” as a security signal: monitor for requests that attempt to extract system messages/policies; alert on abnormal probing behavior; include prompt leakage in red-team scripts.
- Standardize safety system messages and keep them minimal: use system messages to steer behavior, but keep sensitive logic out; Microsoft’s guidance is explicit that system messages work best as one layer and should align with broader safety strategy (Azure OpenAI safety system messages).
Trend #10: Model/IP Extraction Becomes a Strategic Risk — Defending Against “Distillation Theft” and Model Stealing
From 2026 through 2028, model security stops being an internal R&D concern and becomes a strategic risk category: competitors and adversaries will try to replicate your capabilities by extracting value from your deployed models—through systematic querying, “distillation,” side-channel approaches, or abuse of access paths around inference endpoints.

This is no longer a niche academic topic. OWASP explicitly lists Model Theft as a top risk for LLM applications (LLM10), framing it as unauthorized access or extraction that can lead to IP loss, competitive disadvantage, and misuse (OWASP Top 10 for LLM Applications and the specific write-up: OWASP LLM10: Model Theft). NIST’s adversarial machine learning taxonomy also classifies model extraction as a model privacy attack class and describes it alongside related inference attacks (NIST Adversarial Machine Learning — 2025 PDF).
The winners will treat models like crown-jewel services: rate-limited, behavior-monitored, watermark-protected where applicable, and architected so that outputs don’t become a free training dataset for someone else.
Article content
The shift is from “protect the weights” to protect the capability—because attackers increasingly steal functionality without ever touching your training pipeline.
Three forces converge here:
1) Distillation turns your API into someone else’s training set Distillation is a legitimate technique—until it’s used to replicate proprietary behavior without authorization. In February 2026 reporting, Anthropic alleged “industrial-scale distillation attacks,” describing large-scale, automated interactions designed to extract useful behavior from its Claude models (reported by the Financial Times and Business Insider). Whether or not every claim holds in court, the signal is clear: leading model providers now treat output-harvesting as an adversarial practice at scale.
2) Extraction expands beyond weights to the real IP: fine-tunes, policies, evals, and agent behavior In practice, the most valuable “model IP” often isn’t the base model—it’s the combination of fine-tunes, routing prompts, safety policies, evaluation sets, tool-use behavior, and domain-specific performance that took time and money to build. Research surveys are now explicitly focused on LLM-specific extraction pathways and defenses, treating model extraction as a security threat to deployed language models and a risk to IP and privacy (arXiv survey PDF, 2025; ACM survey entry, 2025: ACM DL).
3) “Model stealing” is part of a broader adversarial ML landscape that enterprises must operationalize Model extraction sits alongside model inversion, membership inference, and other privacy attacks. NIST explicitly categorizes model extraction and related inference attacks within adversarial ML taxonomies, which is a strong indicator this is moving into the mainstream security vocabulary (NIST AI 100-2e2025). MITRE’s ATLAS knowledge base is also widely used to structure adversary behaviors against AI-enabled systems—useful when you want to treat model theft as a threat-model item rather than an abstract research topic (MITRE ATLAS).
Business impact
- Competitive loss: differentiated capabilities can be cloned faster than your normal product cycles.
- Cost escalation: “model scraping” can drive inference spend spikes, rate-limit conflicts, and service degradation.
- Safety regression risk: copied/distilled models may lack safeguards, raising downstream ecosystem risk (and reputational blowback if your outputs enabled it).
- IP and compliance exposure: fine-tune data, prompts, and internal policies can leak through extraction-adjacent paths (especially when combined with prompt leakage and indirect injection trends).
CXO CTAs
- Treat model endpoints as high-value services, not generic APIs: enforce strong authentication, tenant isolation, anomaly detection, and throttling tuned to extraction patterns (OWASP’s Model Theft framing is a good baseline: OWASP LLM10).
- Instrument for “extraction-shaped traffic”: watch for high-volume, systematic querying, distribution shifts, repeated paraphrasing, and probing patterns—especially from new accounts or proxy infrastructure (signals consistent with the kinds of “industrial-scale” behavior described in the Anthropic reporting: FT).
- Limit output value where feasible: apply response shaping, throttling of high-value capabilities, and selective refusal for suspicious query patterns; don’t provide verbose reasoning traces or extra tokens when not needed.
- Protect the “capability bundle,” not just the base model: secure fine-tunes, routing prompts, evaluation harnesses, tool-use policies, and agent workflows as governed assets (this links directly to your prior Trend #9 on prompt/policy leakage).
- Add extraction to your adversarial ML threat model: align internal red-teaming with adversarial ML categories like model extraction and inference attacks as framed by NIST, and map them to operational controls (NIST AI 100-2e2025; MITRE ATLAS).
Trend #11: Context Supply Chain Becomes Tier-0 Security — Protecting the “Instructions Around the Model”
From 2026 through 2028, many enterprises will realize their most sensitive AI assets aren’t model weights. They’re the things that steer the model: system prompts, policy prompts, routing templates, orchestration logic, tool instructions, and agent runbooks—the “context supply chain” that quietly determines what an AI system does.
This is no longer hypothetical. Modern agent platforms explicitly let teams edit and override base prompt templates and step logic (which effectively becomes executable control logic in text form), as documented in services like Amazon Bedrock Agents’ “advanced prompt templates” capability (AWS Bedrock advanced prompt templates). And as ecosystems like Model Context Protocol (MCP) mature, connectors can ship server-defined prompt templates that pre-package instructions and workflows—meaning your context can now be partially authored outside your org (arXiv: Security and Safety in the Model Context Protocol Ecosystem, Dec 2025).
The winners will treat context like code: owned, versioned, access-controlled, integrity-checked, and continuously tested—because context tampering is behavior tampering.
Article content
The shift is from securing “models and data” to securing the instruction layer that binds models to enterprise actions.
Three forces converge here:
1) Context is becoming the real control surface in agentic systems In agent stacks, prompts are not just “text.” They encode routing decisions, escalation rules, tool selection, and action constraints. That’s why OWASP’s GenAI security guidance frames LLM applications as supply chains susceptible to multiple vulnerabilities across training data, deployment, and the surrounding components—including the prompt and retrieval surfaces that influence behavior (OWASP LLM01: Prompt Injection and the broader OWASP Top 10 for LLM Apps). When context changes quietly, the system’s behavior changes quietly—often without triggering classic security alerts.
2) “Context tampering” becomes a durable compromise vector Unlike a one-time jailbreak, context compromise can be persistent: a modified routing prompt, a poisoned orchestration template, or a malicious “best-practice” connector prompt can keep influencing decisions over time. MITRE’s recent ATLAS OpenClaw investigation explicitly calls out “context poisoning” and highlights a common failure mode: memory and context are undifferentiated by source, with untrusted inputs stored alongside privileged instructions—making persistent compromise easier (MITRE ATLAS OpenClaw Investigation PDF, Feb 2026).
3) The ecosystem externalizes parts of your context supply chain As organizations adopt connectors, tool servers, and orchestration frameworks, context increasingly comes from outside the core application repo: vendor connectors, shared prompt libraries, workflow templates, and agent “skills.” MCP’s ecosystem discussion is a leading indicator here: “server-defined templates” can package resources and instructions for workflows, which is powerful—and also a supply-chain risk if not governed (arXiv MCP ecosystem paper). The net effect: context becomes an enterprise dependency graph—and dependency graphs must be secured.
Business impact
- Silent behavior drift: assistants start taking different actions or revealing different data because a template or routing prompt changed.
- Stealth persistence: attackers don’t need ongoing access if they can plant durable instructions in context stores, prompt libraries, or orchestration layers.
- Audit and compliance risk: inability to answer “what instruction caused that action?” blocks regulated deployments and increases post-incident ambiguity.
- Operational fragility: teams ship prompt updates like config tweaks, but those updates change security posture just like code changes.
CXO CTAs
- Stand up a “Context Registry” as a governed asset inventory: system prompts, routing prompts, tool policies, orchestration templates, connector-provided prompts, and memory policies—each with an owner, purpose, risk tier, and lifecycle rules (this is the practical extension of treating context as tier-0).
- Treat context like code in the SDLC: version control, code review, approvals, automated tests, and rollback for prompt and orchestration changes—mirroring how platforms already let you override base prompts and steps (e.g., AWS Bedrock advanced prompt templates).
- Implement integrity controls for context artifacts: signing, checksum verification, and controlled deployment paths so templates cannot be silently swapped or modified.
- Separate and label trusted vs untrusted memory/context sources: MITRE’s OpenClaw findings show why undifferentiated memory is dangerous; establish trust levels, expiry, and “do not execute instructions from retrieved content” boundaries (MITRE ATLAS OpenClaw PDF).
- Continuously test for context poisoning and drift: red-team the orchestration layer, prompt libraries, and connector prompts, not just the chat interface—aligned with OWASP’s framing of prompt injection risk expanding across the LLM app supply chain (OWASP LLM01).
Trend #12: Retrieval Authorization Becomes the New Access Boundary — “Permissioned Context” as a Security Requirement
From 2026 through 2028, the most common “GenAI breach” pattern won’t look like a database dump. It will look like a helpful assistant answering a reasonable question… using a document the user was never entitled to see.
This is the moment enterprises learn that retrieval is access. If your RAG system can fetch it, your model can summarize it—and if your model can summarize it, you’ve effectively created a new data access path. OWASP’s 2025 Top 10 for LLM Apps explicitly warns that poorly managed LLM systems can retrieve and disclose sensitive content, elevating Sensitive Information Disclosure as a top-tier risk and calling out retrieval behavior as a central failure mode (see the OWASP PDF: OWASP Top 10 for LLM Applications 2025).
The winners will treat retrieval as a first-class security control: identity- and entitlement-aware retrieval, auditability, and privacy-preserving patterns—not “we’ll just rely on the model to be careful.”
Article content
The shift is from access control on systems to access control on context—because in AI systems, what enters context determines what can be disclosed (and later, what can drive actions).
Three forces converge here:
1) RAG creates a new “shadow data interface” that bypasses traditional application boundaries Users don’t need direct access to the repository to get value from it—only the ability to ask questions that cause retrieval. That is why document-level security is now being productized as a first-class pattern in enterprise RAG implementations. Microsoft’s own reference guidance for securing RAG chat apps is blunt: “make sure each user receives an answer based on their permissions,” and it describes implementing document-level access control fields and filtering retrieval results by user/group identity rather than assuming the search layer “just handles it” (Microsoft Learn: chat document security filtering for RAG apps).
2) Permissioned context becomes mandatory when agents retrieve on behalf of users (and other agents) The failure mode isn’t only disclosure—it’s delegation without guardrails. As AI systems evolve into agents that retrieve, plan, and act, the authorization model must support delegated access safely. A February 2026 NIST NCCoE concept paper on software and AI agent identity/authorization explicitly discusses delegated access mechanisms (OAuth/OIDC) and fine-grained policy approaches (including NGAC), reflecting how quickly authorization is becoming central to agentic systems (NIST NCCoE: Software and AI Agent Identity & Authorization concept paper, Feb 2026). The point for leaders: if you can’t express who is retrieving, on whose behalf, under what consent, with what scope, your RAG system will fail a serious security review.
3) “Security trimming” and policy filtering move from feature to baseline—plus PETs where risk demands it In real enterprise deployments, the practical control is retrieval-time filtering: the system retrieves only what the user is entitled to see, even if the index contains everything. Microsoft has described “security trimming” as essential in agent knowledge retrieval—ensuring responses reflect user permissions and sensitive content stays protected (Microsoft TechCommunity: security filters in agent knowledge retrieval). And as enterprises push GenAI into regulated workflows, privacy-enhancing techniques stop being theoretical. The Cloud Security Alliance’s guidance on data security in AI environments explicitly calls out RAG patterns and recommends retrieving from encrypted, access-controlled repositories and applying privacy/security controls around embeddings and retrieval (Cloud Security Alliance: Data Security within AI Environments).
Business impact
- Prevents “RAG as an exfiltration channel”: stops inadvertent leakage where the model simply summarizes what it can retrieve.
- Unlocks safer enterprise-wide rollout: product teams can scale assistants without constant one-off “this dataset is special” exceptions.
- Improves audit defensibility: you can show which documents were retrieved, why they were eligible, and what policy was applied.
- Reduces secondary risk: permissioned retrieval is a prerequisite for safe agentic tool use—because retrieval often drives actions.
CXO CTAs
- Make retrieval entitlement-aware by design (“permissioned context”): retrieval must obey identity and group membership, not just query relevance—exactly the pattern Microsoft documents for secure RAG chat apps (Microsoft Learn: document security filtering).
- Treat delegated retrieval as an authorization problem, not a prompt problem: define how agents act on behalf of users, how consent is represented, and how scope is enforced—aligned with NIST’s active work on agent identity and authorization for delegated access (NIST NCCoE concept paper).
- Implement retrieval-time security trimming and log it: filter results at query time; log which documents were eligible and returned; make this evidence easy to produce (security trimming is framed as essential in Microsoft’s agent retrieval guidance: TechCommunity security filters).
- Use PETs selectively where the data warrants it: for the highest-sensitivity domains (health, finance, regulated PII), plan privacy-preserving patterns (clean rooms, differential privacy/federated approaches) as part of retrieval and analytics controls—consistent with CSA’s AI data security recommendations around access-controlled retrieval and embedding governance (CSA guidance).
- Make “retrieval authorization failure” a breach-class incident: treat it like improper access to a data store—because functionally, that’s what it is.
Trend #13: Knowledge Ingestion Poisoning Becomes the New Injection — When “Sources of Truth” Become the Payload
From 2026 through 2028, attackers will increasingly stop trying to beat your model directly and instead poison what your model learns from at runtime: the wikis, tickets, PDFs, emails, product docs, and KB articles that feed retrieval and grounding.
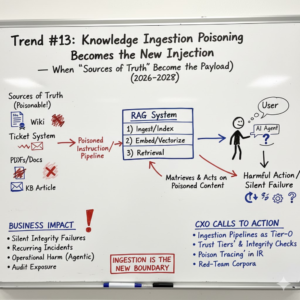
This is the quiet version of prompt injection. Instead of placing a malicious instruction in a chat, the adversary places it in a place your system trusts—then waits. When your RAG system retrieves it weeks later, the model confidently repeats it, escalates it, or (in agentic setups) acts on it.
Academic and industry signals are converging fast here. Research is now demonstrating practical “knowledge poisoning” attacks against RAG systems that can succeed by poisoning even a single document while still influencing complex, multi-hop queries (see EMNLP Findings 2025: One Shot Dominance: Knowledge Poisoning Attack on …). The defensive side is also maturing: work like RAGForensics focuses specifically on tracing poisoned texts in a RAG knowledge base—an implicit admission that poisoning will be a recurring incident class, not a one-off anomaly (ACM: RAGForensics).
The winners will treat ingestion pipelines as security-critical systems: verified sources, controlled publishing, provenance, integrity checks, and “trust tiers” for corpora—because poisoning the knowledge base is often easier than compromising the model.
Article content
The shift is from securing “the model” to securing the truth supply chain—what gets ingested, indexed, embedded, and later retrieved as grounding.
Three forces converge here:
1) RAG turns knowledge bases into executable influence In classic security, a compromised wiki page is bad PR. In RAG systems, a compromised wiki page can become a privileged input to decision-making. Recent papers frame this directly: RAG improves factuality, but it also creates a new vulnerability class—adversaries manipulate the retrieval corpus so the system retrieves and trusts poisoned content (see an overview framing of RAG poisoning risk: arXiv: Understanding Data Poisoning Attacks for RAG). When the retrieved text is later used to justify answers, it becomes a credible source even if it was planted.
2) Poisoning is realistic because “sources of truth” are editable, distributed, and often unaudited Most enterprise corpora are built on systems designed for collaboration—not adversarial integrity. Tickets, docs, and wikis are writable by many roles; vendors contribute documents; emails flow in; shared drives become dumping grounds. Attackers don’t need to defeat your access controls everywhere—just find one place that later gets indexed. Research is now explicitly showing that poisoning attacks can manipulate RAG outputs by injecting poisoned texts into the knowledge database (arXiv: Practical Poisoning Attacks against Retrieval-Augmented Generation). That’s the core insight: ingestion is the new boundary.
3) Defenders are being forced to treat poisoning as an AI supply chain problem OWASP formalizes this direction by naming “Data and Model Poisoning” as a distinct LLM risk category—explicitly including embedding data and other pipeline components, not just pretraining data (OWASP LLM04: Data and Model Poisoning). Microsoft’s security planning guidance for LLM applications also calls out data poisoning attacks as part of the threat model leaders should plan for in high-risk and autonomous scenarios (Microsoft Learn: Security planning for LLM apps). On the broader threat-model side, MITRE’s AI security work explicitly discusses poisoning data stored for operations and the difficulty of detecting backdoor triggers, reinforcing that poisoning is not purely academic (MITRE SAFE-AI full report PDF).
Business impact
- Silent integrity failures: the system “sounds right” while being wrong—because the poison is now in the grounding source.
- Recurring incidents: the same poisoned content gets retrieved repeatedly until you find and remove it; “fixing one response” doesn’t fix the system.
- Operational harm in agentic workflows: poisoned KB entries can trigger unsafe actions (wrong runbooks executed, wrong systems queried, wrong change steps recommended).
- Audit exposure: inability to show what source entered context and why it was trusted undermines defensibility in regulated environments.
CXO CTAs
- Treat ingestion pipelines as tier-0 systems: require controlled publishing, authenticated contributors, and change tracking for high-sensitivity corpora (security runbooks, HR/finance procedures, customer policies). Poisoning is easiest where content is editable and unaudited—so remove “anonymous truth” from critical knowledge paths.
- Implement “trust tiers” for corpora: not all sources are equal. Separate “authoritative” sources (signed, owned, reviewed) from “collaborative” sources (editable, lower-trust) and from “external” sources (vendor PDFs, web content). Retrieval should weight and filter by trust tier. This aligns directly with the idea that poisoning of embedding data and corpora is a first-class risk (OWASP LLM04).
- Add provenance and integrity checks to ingestion: verify documents at ingest time (origin, hash, signature where possible), and keep tamper-evident change history so you can trace when poison entered. This is the ingestion-side complement to the digital provenance control plane you established in Trend #5.
- Make “poison tracing” part of incident response: build the ability to identify which retrieved text caused harmful outputs and remove/quarantine it. Research like RAGForensics is a useful signal that traceback tooling is becoming necessary.
- Red-team the corpora, not just the chat: simulate poisoning via tickets, wikis, and vendor docs—then test whether retrieval surfaces it, whether the model treats it as instruction, and whether downstream tools can be influenced (consistent with Microsoft’s broader security planning approach that explicitly includes data poisoning in the threat model: Microsoft Learn).
Trend #14: Vector/Embedding Leakage and Inference Risks Mature — When “Numeric Representations” Become Reconstructable
From 2026 through 2028, a core assumption breaks: embeddings are not “safe because they’re numbers.” In many real deployments, embeddings behave like compressed representations of sensitive text that can be abused, reconstructed, or inferred—especially when they sit in multi-tenant vector databases, are reused across workflows, or are exposed through overly broad retrieval.
OWASP now formalizes this as a first-class risk area (LLM08: Vector and Embedding Weaknesses), explicitly warning that embeddings can enable unauthorized access and sensitive-data leakage when access controls and retrieval boundaries are weak. At the research edge, embedding inversion is also getting cheaper: the 2025 ALGEN few-shot inversion work lowers the cost/complexity of reconstructing text from embeddings in widely used vector database settings.
The winners will treat embeddings as sensitive assets: protected where needed, governed by strict access controls, segmented by tenant and purpose, and designed so retrieval does not become “inference by proxy.”
Article content
The shift is from “secure the model and the dataset” to securing the representation layer—embeddings, vector stores, and retrieval behavior.
Three forces converge here
1) Embeddings are becoming reversible enough to matter The old posture—“embeddings aren’t readable”—is aging fast. Reconstruction and inversion techniques increasingly show that attackers can recover meaningful text fragments or infer sensitive attributes under realistic conditions. The trendline matters as much as today’s accuracy: lower-assumption attacks are emerging and targeting common vector DB patterns.
2) Multi-tenant vector stores and cross-context reuse create real leakage paths In practice, leakage is often an architecture failure, not a math failure. Common causes include shared indexes across teams/customers, weak namespace isolation, embedding reuse across unrelated workflows, and over-broad semantic recall that returns “similar enough” sensitive content. OWASP’s framing is direct: weak embedding access control can lead to retrieval and disclosure of sensitive information.
3) Privacy-preserving RAG moves from academic idea to practical pressure As RAG expands into regulated domains, enterprises face an uncomfortable reality: even without raw documents, embedding-based retrieval can leak privacy through reconstruction and structural inference. Privacy-preserving RAG is moving from “research nice-to-have” to a necessary option in high-sensitivity environments, even with performance trade-offs.
Business impact
- Quiet sensitive disclosure via semantic retrieval, even when users lack direct document access
- Cross-tenant leakage when retrieval boundaries are weak
- Regulatory/contractual exposure if embeddings derived from PII or regulated data can be reconstructed or inferred
- Higher blast radius in agentic systems once sensitive context is retrieved and reused
CXO CTAs
- Treat embeddings as sensitive data, not harmless metadata; classify vector indexes by sensitivity
- Enforce tenant and purpose isolation in vector stores; avoid “one index to rule them all”
- Make retrieval authorization non-negotiable: entitlements and security trimming must be enforced at retrieval time
- Assume inversion gets cheaper: minimize embedding exposure, rate-limit probing, detect scraping/systematic similarity abuse
- Use privacy-preserving retrieval/RAG patterns selectively for high-sensitivity domains, with explicit performance trade-off decisions
Trend #15: Orchestration Integrity Becomes an Attack Surface — Tool Routers, Planners, and GraphRAG Under Pressure
From 2026 through 2028, the highest-leverage attacks won’t target “the model.” They’ll target orchestration: the router that selects tools, the planner that decomposes tasks, and the retrieval logic (including GraphRAG) that determines what the model sees. If orchestration is compromised, the system can behave legitimately wrong—using valid credentials and approved connectors.
GraphRAG is a clear signal that retrieval is becoming more structured and powerful—and therefore more security-critical. Recent work also shows GraphRAG can introduce graph-specific poisoning leverage: shared relations can be manipulated to affect multiple queries, creating wider blast radius than simple RAG poisoning.
Article content
The shift is from “secure prompts” to securing decision logic: how tools are chosen, how context is assembled, and how actions are authorized.
Three forces converge here
1) Tool routing is privilege selection In agentic systems, choosing a tool is effectively choosing an authority level. If routing is influenced (via prompt injection, indirect injection, or poisoned context), attackers can trigger objective drift or steer execution toward risky tools.
2) Tool ecosystems create supply-chain risk Tool descriptions/templates can carry malicious instructions (tool poisoning), and approved tools can change behavior later (rug pulls). This is increasingly discussed in MCP-style tool ecosystems, along with mitigations for squatting and rug-pull attacks.
3) GraphRAG adds new integrity and inference failure modes Graph structure can amplify poisoning: compromise a shared relation and multiple queries are affected. This creates multi-query leverage that standard RAG defenses may miss.
Business impact
- Wrong tool, right credentials: harmful but valid-looking actions
- Multi-query compromise from a single poisoned relation/template
- Audit gaps when teams can’t explain why the agent chose a given tool/path
CXO CTAs
- Treat orchestration as production code: versioning, reviews, tests, rollback for routers/planners/tool policies
- Make tool choice policy-gated: model proposes, policy decides
- Harden tool definitions: signed metadata, schema-bound parameters, sandboxing, continuous monitoring
- Red-team orchestration (objective drift, malicious tool selection, tool shadowing, graph poisoning)
- Log decisions, not just actions: why a tool was selected, what context drove it, and what policy checks ran
Trend #16: Agent Sprawl Becomes the New Shadow IT — Unowned Autonomy, Real Permissions
From 2026 through 2028, the fastest-growing “application estate” won’t be SaaS—it will be agents: copilots, workflow bots, and task automations built by business teams with real connectors, real tokens, and little lifecycle governance.
The winners will treat agents like production services: registered, owned, permission-scoped, monitored, and decommissioned—because unowned autonomy becomes a compliance and breach multiplier.
Article content
The shift is from controlling apps to controlling autonomous actors—including who created them, what they can access, and what they can do.
Three forces converge here
1) Low-friction agent building collapses deployment barriers Agent frameworks and enterprise tooling make it easy to build “just one more helper.” Without a registry and standards, that quickly becomes uncontrolled proliferation.
2) Agents create new access paths that bypass usual controls Agents often ship with broad connectors (mail, files, tickets, repos) and long-lived tokens. Teams also reuse service accounts or shared credentials, creating duplicate lateral-movement paths.
3) The hardest risk is action authority, not just data access An unowned agent is not only an exfiltration risk—it is an execution layer that can send messages, close tickets, change configs, or trigger workflows, often with weak approval logic.
Business impact
- Hidden blast radius: no fast answer to “how many agents exist and what can they do?”
- Compliance blind spots: untracked processing, unclear accountability for automated actions
- Incident complexity: unclear ownership + incomplete logs slow investigation
CXO CTAs
- Mandate an Agent Registry (owner, purpose, data scope, tool scope, expiry) before production access
- Default to least privilege + time-bounded access (scoped permissions, short-lived tokens, JIT approvals)
- Define safe-to-run requirements: logging, config change control, kill switch, rollback
- Create agent decommissioning rules: auto-expiry + periodic recertification for high-privilege agents
- Adopt a formal agent identity/authorization standard (NIST’s direction here is a strong anchor)
Trend #17: Excessive Agency Becomes the Dominant Failure Mode — When “Helpful” Turns Into “Authorized Harm”
From 2026 through 2028, the most damaging AI incidents won’t come from hallucinations. They’ll come from excessive agency: agents with too many tools, too much data access, and too much freedom to act.
OWASP explicitly names Excessive Agency (LLM06) as a top LLM risk. The security story shifts from “the model made a mistake” to “the system was allowed to do too much.”
Article content
The shift is from building smart agents to building bounded agents—systems that can assist broadly but act narrowly.
Three forces converge here
1) Tool sprawl becomes privilege sprawl Every connector (mail, files, tickets, repos, cloud consoles) adds action surface. “Just one more tool” gradually produces an agent with near-admin reach—without admin-grade controls.
2) Prompt/context attacks become action attacks Once an agent can act, prompt injection and indirect injection are no longer content issues—they become workflow compromise: wrong message, wrong ticket, wrong setting, wrong payment step. The common chain is LLM01 (prompt injection) + LLM06 (excessive agency): shape intent, then let permissions do the damage.
3) Lack of reversibility turns mistakes into incidents Many enterprise workflows are not designed with undo/rollback. When agents act in systems of record, incorrect actions become expensive rework—or breach-class events.
Business impact
- Unauthorized-but-valid actions that look legitimate in logs
- Higher blast radius from one compromised session or poisoned context source
- Slower response while teams untangle what the agent changed across tools
CXO CTAs
- Define a minimal tool budget per agent
- Separate read from act; tightly scope and policy-gate write/execute
- Use step-up controls for high-risk actions (approvals, dual control, JIT)
- Add execution-time guardrails: allowlists, rate limits, sandboxing
- Design for reversibility: rollback/undo or compensating controls for agent-initiated actions
Trend #18: Agent Identity & Accountability Becomes a First-Class Control Domain — “Know Your Agent” in Practice
From 2026 through 2028, enterprises will stop treating agents as features and start treating them as actors. If an agent can retrieve sensitive context, call tools, and trigger actions, the organization must be able to answer: Which agent did this? Who owns it? What authority was delegated? What approval path was used?
This shift is already being formalized in industry thinking, including NIST NCCoE work on software and AI agent identity and authorization focused on delegated access and authorization models.
Article content
The shift is from “agents use credentials” to agents having identity, scope, and auditability—like human users, but with stricter defaults.
Three forces converge here
1) Delegation without identity kills accountability If agents rely on shared service accounts, long-lived tokens, or vague app identities, you lose provable attribution and authority chains. In regulated environments, this becomes an audit failure quickly.
2) Agent access must be provably scoped and time-bound Standing privilege is risky for humans and worse for always-on agents. The pattern shifts toward JIT access and ephemeral authorization.
3) Auditability must capture intent and delegation—not just API calls Classic logs show what happened. Agent accountability needs logs for why: which user/task the agent served, what context was used, what policy checks ran, and what approvals were obtained.
Business impact
- Lower blast radius through explicit delegation boundaries
- Faster investigations via clear identity + decision logs
- Better compliance through traceable delegated authority and non-repudiation
CXO CTAs
- Create an Agent Registry with mandatory ownership + scope before production
- Make agent identity unique and cryptographic (no shared identities/tokens)
- Enforce explicit delegation rules for “act on behalf of” access
- Default to ephemeral authorization (short-lived tokens, JIT approvals, step-up for irreversible outcomes)
- Log/review agent actions like privileged operations (identity, delegation chain, retrieved sources, tools, policy decisions, approvals)
Trend #19: Persistent Memory and State Become Durable Compromise Vectors — “Sticky” Instructions That Survive Sessions
From 2026 through 2028, a new compromise pattern becomes common: not account takeover, but state takeover. Agents with memory—conversation history, user preferences, long-term notes, vectorized memories, cached tool results—create a persistence layer where malicious instructions can survive and re-trigger later.
MITRE’s OpenClaw investigation directly highlights this weakness: memory/context poisoning, especially when trusted and untrusted sources are mixed, can create durable compromise that is hard to detect.
Article content
The shift is from securing sessions to securing state—what an agent remembers, stores, and reuses.
Three forces converge here
1) Memory becomes a new persistence layer Attackers don’t need continuous access if they can plant durable instructions in memory (e.g., trust changes, exfil behaviors, priority overrides). That persistence outlives a single chat and can survive device/user changes.
2) Memory poisoning looks like normal behavior Unlike malware, poisoned memory often produces plausible outputs. The agent still authenticates, uses approved tools, and writes valid logs—just guided by contaminated state.
3) Memory usually lacks governance Many systems treat memory as a convenience feature, not a controlled asset. Without trust labels, TTLs, and review, memory becomes an ideal hiding place for long-lived manipulation.
Business impact
- Repeat incidents: behavior returns because poisoned state remains
- Stealth policy drift without a visible change event
- Harder forensics across time as investigators reconstruct memory influence
CXO CTAs
- Separate trusted vs untrusted memory sources; never mix system policies with raw retrieved content in one memory channel
- Add TTL + recertification for memory, especially high-impact memories affecting tool use/decisions
- Make memory writable only via controlled flows (explicit confirmation, audit logging, easy deletion)
- Scan memory for instruction-like persistence patterns (“always,” “ignore policy,” external exfil destinations)
- Add a memory kill-switch to IR playbooks (wipe/quarantine state as standard response)
Trend #20: Agent-to-Agent Lateral Movement and Toolchain Ecosystem Attacks — When Workflows Become the New Network
From 2026 through 2028, lateral movement won’t just mean host to host. It will increasingly mean agent to agent across workflow graphs: one compromised agent pivots into other agents, shared tools, shared memory stores, shared indexes, and shared connectors—because the enterprise increasingly operates as a mesh of automations.
The warning lights are already on. MITRE’s OpenClaw investigation shows how agent memory/context poisoning and weak trust-boundary separation can enable durable compromise across agent workflows. Meanwhile, MCP-style tool ecosystems introduce tool-level supply chain risks such as tool poisoning and “rug pull” dynamics, where tool behavior changes after approval.
Article content
The shift is from defending endpoints to defending workflow graphs—how agents, tools, and connectors form a new traversal map.
Three forces converge here
1) Workflow graphs become the new lateral movement map Agents share vector stores, orchestration layers, tool routers, ticketing integrations, messaging systems, and identity tokens. If one node is compromised, the attacker follows the graph—often using legitimate API calls.
2) Toolchain ecosystems become a supply chain Agents increasingly rely on reusable tools and connectors, creating “toolchain attacks”:
- Tool poisoning (malicious instructions in metadata/descriptions)
- Tool shadowing (lookalike tools selected by mistake)
- Rug pulls (approved tools later change behavior)
3) The “autonomous insider” pattern becomes real A compromised agent behaves like a tireless privileged operator: persistent, fast, and able to retry until it succeeds—especially when tools are broad and action gating is weak.
Business impact
- Stealth persistence via OAuth grants, tool permissions, and shared integrations (instead of malware)
- Blast-radius amplification across agents and tools
- Harder investigations spanning agents, tool servers, orchestrators, and memory layers
CXO CTAs
- Treat agents and tools as a segmented mesh: isolate identities, permissions, and data access by domain
- Enforce tool allowlists + signed tool definitions: immutable-by-version, reviewable, and monitored for change
- Require action gating for cross-agent operations (messages, approvals, access changes, money movement)
- Instrument agent graph telemetry: track agent-to-agent calls, shared resource access, and unusual tool selection patterns
- Add toolchain compromise to IR playbooks: revoke tool permissions, rotate secrets, quarantine tool servers, wipe agent state
Trend #21: Shadow GenAI Tools Create Unmanaged Exfiltration Paths — “Invisible Work” With Real Data
From 2026 through 2028, the most common GenAI data leak won’t be a sophisticated breach. It will be employees using unsanctioned AI tools and agents—personal accounts, rogue plugins, or “quick copilots”—that sit outside corporate logging, DLP, and retention.
This is already measurable: Microsoft reports 29% of employees have used unsanctioned AI agents for work tasks. Netskope has also reported a sharp rise in GenAI data-policy violations, including uploads via personal/unmanaged accounts. Gartner has warned shadow AI is on track to cause breaches at meaningful scale.
Article content
The shift is from “Shadow IT” to Shadow AI, where the data path is copy/paste, upload, or connector-based—harder to see and easier to justify (“I’m just being productive”).
Three forces converge here
1) Personal accounts bypass enterprise controls by default Employees paste sensitive text, upload files, or connect tools using consumer identities—removing security visibility and enforcement.
2) Agents and plugins turn leakage into ongoing exposure It’s no longer just one prompt. Plugins, connectors, and agents can create persistent third-party data flows, often with broader scope than intended.
3) Blocking doesn’t work at enterprise scale Users route around friction. Shadow AI combines ease-of-use and opacity, making risk larger than traditional Shadow IT.
Business impact
- Unlogged exposure of PII, source code, contracts, customer data
- Compliance drift (retention, residency, audit violations)
- IP leakage outside policy
- Incident ambiguity: “Where did this data go?”
CXO CTAs
- Make sanctioned tools better than unsanctioned tools (fast, easy, workflow-fit)
- Inventory Shadow AI like Shadow IT: discover usage across browsers, endpoints, SaaS logs, and network telemetry
- Set enforceable allowed-use rules (paste/upload/summarize/embed/export)
- Control identity, not just apps: prevent personal-account access to high-risk tools from managed devices
- Treat GenAI data violations as a key risk metric (uploads, sensitive-data events, personal-account usage)
Trend #22: Malware “Push” Through AI Assistants and Agents Becomes Practical — Agents as the Execution Layer
From 2026 through 2028, attackers won’t just use AI to write malware faster. They’ll use AI assistants and agents to deliver and execute it—because agents increasingly have the two things malware loves: tool access and legitimacy.
This moved from theory to demonstration in February 2026: a prompt-injection exploit against the coding agent Cline was used to distribute the “OpenClaw” agent onto user machines, showing how a compromised agent workflow can become a software delivery path.
Article content
The shift is from “malware executes on endpoints” to “malware rides on automation”—where the agent is tricked into performing attacker steps.
Three forces converge here
1) Prompt injection becomes execution, not just manipulation If agents can run commands, install packages, change configs, or call admin APIs, successful injection becomes a remote procedure call using the agent’s privileges.
2) Skill/tool marketplaces become a malware distribution channel Agents increasingly acquire external skills/tools—effectively downloading code from the internet. Malicious skill files published to agent ecosystems demonstrate how “agent add-ons” become a malware supply chain.
3) AI assistants can be abused as malware infrastructure Once malware lands, AI browsing/assistant features can blend attacker communications into benign-looking activity.
Business impact
- Higher compromise velocity (agents execute multi-step playbooks quickly)
- Harder detection (actions look like legitimate automation)
- New supply chain exposure via skills/tools/plugins
CXO CTAs
- Put runtime boundaries in front of every agent action: separate suggest from execute; require policy checks and step-up approval for high-risk actions
- Treat skills/tools as third-party code: signed packages, allowlists, provenance, continuous scanning
- Harden against prompt-driven execution: constrain parameters, restrict install/exec, sandbox where possible
- Monitor agent behavior telemetry like privileged activity
- Run “agent-as-execution-layer” red-team drills (push installs/config changes via injected content)
Trend #23: Self-Replicating Prompt Patterns (“AI Worms”) Become a Threat Model Class — Containing Propagation, Not Just Compromise
From 2026 through 2028, the real step-change isn’t just that prompt injection works. It’s that prompt injection can replicate—moving across inboxes, ticketing systems, shared docs, RAG corpora, and agent-to-agent handoffs until the organization is effectively infected by instructions.
This is no longer metaphor. Research has demonstrated worm-style self-replicating prompts (“Morris II”) and multi-agent “prompt infection” patterns that spread from one LLM agent to another.
Article content
The shift is from securing a single interaction to securing propagation pathways—because once agents can read + write across systems, the enterprise becomes a replication surface.
Three forces converge here
1) Agents turn content systems into propagation infrastructure Email, tickets, wikis, docs, chat transcripts, and CRM notes become distribution rails. The same connectivity that makes agents useful makes viral prompts feasible.
2) Multi-agent workflows create LLM-to-LLM infection chains One compromised agent can pass malicious instruction patterns to others—creating a new lateral movement fabric.
3) Persistence shifts into memory and corpora (“promptware” persistence) The durable versions plant themselves into email archives, RAG indexes, and agent memory/state so they re-trigger whenever content is summarized or retrieved.
What enterprises get wrong (and why it fails)
- Treating it like classic malware containment: endpoint isolation helps, but payloads may live in docs, tickets, and archives
- Assuming “no one clicked” means “no incident”: zero-click indirect prompt injection can still propagate
- Letting agents auto-forward/auto-write by default: replication requires a write path, and many orgs provide one
Business impact
- Incident scope explosion: graph-wide decontamination (agents + connectors + corpora)
- Operational disruption: quarantines and rebuilds of knowledge stores
- Hidden recurrence: worm returns because memory/corpus remained poisoned
CXO CTAs
- Engineer propagation firebreaks: default-deny cross-system writes unless policy-gated and logged
- Quarantine untrusted content before it becomes shared truth (content trust tiers)
- Add AI worm simulations to IR and measure detect/quarantine/decontaminate times
- Make decontamination first-class: purge/quarantine poisoned docs, KB pages, RAG chunks, memory; re-index with integrity checks
- Instrument for replication signals: outbound bursts, repeated instruction-like phrases, anomalous handoffs, cross-system write spikes
Trend-specific CTA: If a malicious instruction lands in one mailbox or ticket queue today, how many other systems can your agents copy it into—without a human ever approving the spread?
Trend #24: GenAI Changes Software Supply Chain Risk — Faster Code, Faster Compromise
From 2026 through 2028, the dominant software supply chain shift won’t be a new registry weakness. It will be AI-mediated dependency fraud: models (and coding agents) hallucinate plausible package names, attackers register them, and teams install them at speed.
This attack pattern now has a name: slopsquatting.
Article content
The shift is from “developers typo a dependency” to “the model invents one—and the attacker makes it real.”
Three forces converge here
1) Package hallucinations turn AI output into an attacker backlog Coding assistants confidently suggest nonexistent dependencies; attackers monitor and register those names with payloads.
2) Agentic “vibe installs” collapse friction in the riskiest step When agents can fetch/install dependencies automatically, the highest-risk action (introducing third-party code) becomes faster and less reviewed.
3) LLM app stacks add new supply-chain surfaces beyond packages Prompts, tools, connectors, agent templates, and model add-ons also become supply-chain inputs.
Business impact
- Malicious dependency introduction at scale (dev, CI, agent-driven environments)
- Faster compromise velocity as AI increases code churn without proportional review
- Harder attribution (looks like normal development activity until runtime reveals payload)
CXO CTAs
- Make dependency introduction a gated event: allowlists, lockfiles, hash pinning, mandatory review for new packages
- Block agent auto-install by default: agents propose; pipelines/policy decide
- Enforce signed, attested build provenance
- Instrument for phantom dependency signals: first-seen packages, low reputation, unusual registries, AI-assisted commit correlation
- Run a slopsquatting red-team drill
Trend-specific CTA: If an assistant invents a dependency today, what stops your org from being the first to install the attacker’s “brand-new” package tomorrow?
Trend #25: AI Compute Becomes a Monetizable Target — Availability + Cost as Attack Goals
From 2026 through 2028, many “AI attacks” won’t target data first. They’ll target compute and cost models—turning inference into an economic drain, service disruption, or both.
LLMjacking (abusing stolen cloud credentials to run expensive LLM workloads) is now a concrete, observed pattern.
Article content
The shift is from classic DoS (“take it down”) to economic DoS + resource hijack (“make it unaffordable or unusable”) because AI runtimes have a direct cost surface: tokens, tool calls, long context, and GPU time.
Three forces converge here
1) Credential theft becomes compute theft (“LLMjacking”) Attackers compromise cloud principals, discover AI services, and burn GPU/inference capacity for monetization—leaving inflated bills and degraded service.
2) Model DoS gets easier via worst-case execution paths Prompts can maximize generation length, tool loops, or high-cost reasoning paths—exhausting quotas and capacity.
3) Token economics becomes an attack surface (cost-based DoS) Attackers force high token consumption (long contexts, retries, inflated outputs) to burn budget and throttle real users.
Business impact
- Budget shock / mystery spend
- Availability hits via quota exhaustion, latency, degraded UX
- Secondary security exposure via stolen-key AI abuse at scale
CXO CTAs
- Treat spend controls as security controls: caps, burst limits, anomaly alerts, kill switches
- Lock down AI cloud access like tier-0: least privilege, short-lived creds, continuous monitoring
- Put hard runtime ceilings on abuse primitives: max context/output/tool calls/steps, loop detection
- Detect EDoS-shaped and extraction-shaped traffic patterns
- Include cost attacks in IR drills: token floods, tool loops, stolen-key abuse
Trend-specific CTA: If an attacker gets one cloud principal today, how fast can they turn it into GPU burn + quota exhaustion—and how fast can you shut it down without shutting the business down?
Trend #26: Identity-First Intrusion Dominates (Tokens > Passwords) — Session Control Becomes the Perimeter
From 2026 through 2028, many successful intrusions will involve little or no malware. Attackers won’t “hack in”—they’ll log in using stolen sessions, tokens, and recovery paths. In that world, “we had MFA” is no longer a sufficient post-incident explanation.
Article content
The shift is from protecting credentials to protecting sessions and authorization lifecycle—because the asset is no longer the password; it’s the active token and what it can do.
Three forces converge here
1) Session/token theft becomes the new credential theft Attackers target browser sessions, refresh tokens, and identity artifacts that bypass MFA.
2) Phishing-resistant auth rises, so attackers pivot As passkeys/hardware MFA improve, attackers increasingly exploit recovery, helpdesk resets, device enrollment, and token replay.
3) Non-human identities amplify blast radius Workloads, bots, and agents create more tokens, more secrets, and often weaker governance.
Business impact
- Stealthier breaches (activity looks authorized because it is—by token)
- Higher dwell time and wider lateral movement
- Recovery failures become breach multipliers
CXO CTAs
- Treat session lifecycle as tier-0: short lifetimes, continuous access evaluation, device posture gating, rapid revocation
- Harden recovery like privileged access: step-up proofing, dual control, tamper-evident logs, known-good channels
- Reduce standing privilege (especially service accounts/agents); prefer JIT scoped authorization
- Govern non-human identity at scale
- Measure identity resilience: time-to-revoke sessions, contain OAuth grants, safely recover accounts
Trend-specific CTA: If an attacker steals a valid session token today, can you invalidate it everywhere that matters—fast enough to prevent “authorized” damage?
Trend #27: OAuth and Integration Abuse Becomes Stealth Persistence — “Authorized Apps” as the Foothold
From 2026 through 2028, one of the cleanest persistence mechanisms won’t be malware. It will be OAuth grants and authorized apps that look legitimate, survive password resets, and often bypass MFA assumptions—because the user (or admin) technically consented.
Article content
The shift is from “protect accounts” to governing delegated authorization—because attackers increasingly persist through what the platform considers a valid integration.
Three forces converge here
1) Consent becomes the new credential Attackers use consent phishing to get high-privilege OAuth scopes. Once granted, access persists even after password resets.
2) SaaS integration sprawl creates hidden lateral movement paths Thousands of integrations become trust relationships—and trust relationships become traversal paths.
3) Defenders can’t secure what they can’t inventory OAuth grants live in identity platforms; app permissions live across SaaS; logs are fragmented.
Business impact
- Stealth persistence that survives credential resets
- Data exposure via API without endpoint signals
- Lateral movement through approved connectors
- Audit/compliance pain when least-privilege delegation can’t be proven
CXO CTAs
- Default-deny end-user app consent for sensitive scopes; require admin approval for high-risk permissions
- Run continuous OAuth hygiene: review scopes, owner, last-used, risk; expire stale grants
- Build and maintain an integration inventory; treat trust edges like attack paths
- Separate low-risk automation from high-risk delegation with step-up verification/change control
- Make OAuth abuse a standard IR play (revoke grants, quarantine apps, rotate tokens/secrets, retro-hunt API activity)
Trend-specific CTA: Can you name the top 20 third-party apps with access to executive mailboxes and finance files—and revoke them in minutes without breaking the business?
Trend #28: Non-Human Identity Explosion Becomes the Blast-Radius Multiplier — Governance Becomes Survival
From 2026 through 2028, the identity population that matters most won’t be employees. It will be non-human identities (NHIs): workloads, service accounts, APIs, CI/CD runners, bots—and increasingly agents. They outnumber humans, run continuously, and are often more privileged and less governed.
Article content
The shift is from “IAM = people” to IAM = every actor that can call an API—because NHIs drive most interactions, and one compromised NHI can traverse cloud + SaaS at machine speed.
Three forces converge here
1) Attackers pivot to workload identities They’re privileged, under-governed, and ideal for stealth persistence and lateral movement.
2) Secrets sprawl becomes the default failure mode Keys, tokens, certificates, and shared service accounts proliferate across pipelines/integrations; long-lived or reused secrets make compromise and cleanup painful.
3) Agents make NHI governance a board-level risk Agents are effectively NHIs with intent + tool access, pushing this into formal control expectations.
Business impact
- Blast-radius amplification via one leaked workload token
- Stealth persistence through API-native access paths
- Operational fragility because teams delay rotation/revocation to avoid outages
- Audit failure risk when ownership/scope/review of machine identities can’t be proven
CXO CTAs
- Stand up an NHI Registry (owner, purpose, scope, expiry)
- Kill long-lived secrets by default; move to short-lived credentials and rotation automation
- Make service-to-service authorization a primary control surface (least privilege, narrow scopes, continuous verification)
- Instrument NHI behavior like privileged activity
- Extend “Know Your Agent” to every machine actor: unique, time-bounded, explicitly delegated identities
Trend-specific CTA: If one CI/CD runner or service account is compromised today, can you answer—within minutes—where it can go, what it can do, and how to revoke it without taking production down?
Trend #29: Machine-Speed Cyber Ops Becomes Continuous — Offense vs Defense Moves to Runtime
From 2026 through 2028, “good enough” security operations won’t be defined by how many alerts you triage. It will be defined by whether you can detect, decide, contain, and recover at machine speed—with guardrails and evidence.
Article content
The shift is from “SOC as a human queue” to SOC as a continuous control plane—where automation handles safe, repeatable response and humans focus on exceptions, authorization, and recovery decisions.
Three forces converge here
1) Offense accelerates throughput Attackers use AI to scale targeting, tailor pretexts, and iterate faster, compressing defender decision windows.
2) Intrusions become multi-surface by default Identity, SaaS, cloud, endpoints, and human workflows are all in play; response must coordinate across platforms.
3) Automation is required—but unsafe automation is worse than none Winning pattern = governed automation: policy-gated actions, rollback, immutable logging, two-speed response (safe actions automated; destructive actions step-up approved).
Business impact
- Lower loss/dwell time when containment executes in minutes
- Higher resilience when recovery is engineered, not improvised
- Stronger audit defensibility through policy-checked, tamper-evident automation
- Reduced burnout and better signal quality
CXO CTAs
- Define automation-safe containment actions and wire them into playbooks first (session/token revocation, risky OAuth disablement, known-bad egress blocks)
- Build rollback into response by design (quarantine vs delete; disable vs remove)
- Engineer recovery like a product: immutable backups, clean recovery environments, tested restores, crisis comms drills
- Treat segmentation + identity posture as response accelerators
- Measure machine-speed readiness: % of top actions executable safely in <5 min, session revocation time, SaaS quarantine time, restore time
Trend-specific CTA: What portion of your incident response can execute in under five minutes—with policy gates, rollback, and tamper-evident evidence—without waiting for a human to wake up?
Trend #30: Physics-Driven Deadlines Reshape Architecture — Post-Quantum Migration + Confidential Compute + Beyond-Terrestrial Networks
From 2026 through 2028, some of the most consequential security work won’t be triggered by a breach. It will be triggered by physics and standards transitions: post-quantum cryptography timelines, “harvest now, decrypt later” risk, and a perimeter expanding beyond terrestrial networks.

Article content
The shift is from “we’ll upgrade crypto later” to crypto agility + data-in-use protection + new network domains as baseline architecture expectations.
Three forces converge here
1) Post-quantum crypto becomes a hard program The issue isn’t only when a CRQC arrives—it’s harvest now, decrypt later for data needing 10+ years of confidentiality. This forces inventory, crypto agility, and hybrid transitions now.
2) Confidential computing and attestation move into key-release policy As sensitive AI processing expands, enterprises need stronger guarantees for data-in-use and workload integrity—especially for high-risk inference, RAG, and agent actions.
3) NTN / satellite networks expand the perimeter Satellite/NTN increases concentration risk: gateways, ground segments, terminals, and handover points become tier-0 surfaces. Enterprises consuming NTN inherit these risks.
Business impact
- Long-lived confidentiality risk unless crypto agility is engineered now
- Procurement/vendor pressure for PQC-ready and attestation-capable systems
- Stronger AI trust boundaries via TEEs/attestation for sensitive processing
- Expanded operational perimeter spanning satellite↔ground↔enterprise networks
CXO CTAs
- Launch a PQC program now: inventory, dependency mapping, crypto agility, hybrid transition, vendor readiness gates
- Prioritize data with a long secrecy horizon (10+ years)
- Adopt attested workloads for sensitive AI processing and key release policies
- Treat NTN as an enterprise network domain: segment, harden, monitor, and test satellite↔terrestrial incident scenarios
- Build evidence readiness into architecture: crypto inventory, migration status, attestation evidence, executive reporting
Anti-Patterns to Avoid (Why they look good — and why they fail)
Anti-Pattern #1: “Detection will save us” (deepfakes, prompt injection, RAG leaks)
This looks attractive because it feels measurable (“our detector catches X%”). It fails because attackers iterate faster than classifiers, and under pressure, verification beats prediction. Detection still matters, but durable defense comes from provenance, signed approvals, entitlement-aware retrieval, and runtime policy gates.
Anti-Pattern #2: “Give the agent broad access; we’ll tighten later”
This feels efficient because pilots move faster and demos look powerful. It fails because early tool sprawl usually becomes permanent privilege sprawl, and the first real incident becomes authorized harm: valid actions executed through manipulated intent, with logs that appear legitimate.
Anti-Pattern #3: “OAuth/integrations are IT plumbing, not security”
This seems reasonable because integrations are often treated as operational infrastructure owned by app teams. It fails because OAuth grants and SaaS connectors become stealth persistence and lateral movement paths that can survive password resets and bypass MFA assumptions.
One Trend That May Slow Progress: Fragmented Ownership Across Security, AI, Data, Product, and IT
Most of these new control planes sit between teams—retrieval authorization, context integrity, agent identity, tool gating, and provenance. If no one owns them end-to-end, organizations either stall or ship unsafe systems with inconsistent controls.
What prevents the slowdown
A shared reference architecture with security-by-default guardrails, a clear RACI for each control plane (retrieval, context, orchestration, autonomy), and central platforms teams can use without reinventing controls.
Closing Perspective — All-Up CTA
Stop optimizing last decade’s perimeter. Commit to the new control planes: Trust (provenance, signed approvals, known-good channels, tamper-evident evidence), Identity (session lifecycle, OAuth governance, non-human identity discipline), and Autonomy (bounded agency, permissioned context, runtime policy gates, reversible actions).
Enterprise-level CTA
In the next 12 months, re-architect around verifiable trust, identity-first authorization, and autonomy containment—because attackers already have machine speed and synthetic persuasion. Your advantage has to be engineered control.
Leave a Reply