Data Engineering in 2026: The Patterns That Decide Whether You Trust Your Numbers

Why Data Engineering Is at an Inflection Point Now (2026)
For a decade, data engineering strategy was a scale story: centralize data, build pipelines, add a lake or warehouse, and assume “more data + more compute” would eventually translate into better decisions. That framing is running out of road. Not because data is any less strategic—but because the constraints have become explicit, measurable, and unavoidable.
“Data engineering is no longer about moving data. It’s about operating truth as a governed, observable product.”
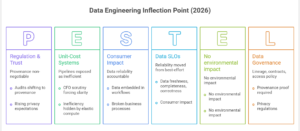
Over the last 24–36 months, three forces have reshaped the agenda.
1) Reliability moved from best-effort to accountable
Data is now directly embedded in operational workflows and AI systems. When data is late, duplicated, drifted, or silently wrong, the failure isn’t a broken dashboard—it’s a broken business process. That’s why leading organizations are shifting from “pipeline uptime” to data SLOs: freshness, completeness, correctness proxies, and consumer impact.
“If you can’t specify and measure data reliability, you don’t have a platform—you have a dependency you can’t control.”
2) Economics turned pipelines into unit-cost systems
Elastic compute didn’t make data cheaper; it made inefficiency easier to hide. Now CFO scrutiny is forcing clarity: cost per metric, per dashboard, per feature set, per model refresh. Full refreshes, uncontrolled backfills, and endless recomputation are being exposed as design failures, not “cloud bills.”
“If you can’t express data cost as unit cost, you don’t have governance—you have invoices.”
3) Regulation and trust made provenance non-negotiable
Across industries, audits are shifting from “do you secure data?” to “can you prove how a number was produced, who touched it, and what it was used for?” Privacy expectations are also rising: minimization, purpose limitation, retention controls. In practice, this turns lineage, contracts, and access policy into engineering primitives—not compliance afterthoughts.
“Lineage isn’t metadata. It’s defensibility.”
This is where many enterprises misread the moment. They treat ingestion, transformation, orchestration, quality, governance, cost, and AI readiness as separate initiatives—each optimized locally. In reality, they’re converging into one operating model: data as an execution layer for decisions, automation, and products.
In 2026–2028, the winners won’t be the organizations that “build more pipelines.” They’ll be the ones that build a fabric that can sense (telemetry + data signals), reason (contracts + policies + economics), and act (reprocessing + containment + serving)—with controlled failure modes.
If data’s first era was “collect and centralize,” the next era is “decide, guarantee, and operate—continuously.”
When you’re ready, I’ll write Trend #1 in the same style using your template structure (Anchor Insight → Shift → Drivers → Business Impact → Leader Actions → CTA).
Trend #1: Contract-First Ingestion — Time Semantics Become a Business Decision (Batch, Streaming, CDC)
From 2026 through 2028, ingestion stops being “how we get data in” and becomes how the enterprise defines truth over time. Most organizations already run a messy mix of batch loads, event streams, and CDC feeds—but without consistent rules for ordering, late-arriving changes, deletes, and replay. That’s why the same metric can be “right” in one system and “wrong” in another, depending on when you ask.
Anchor insight “Ingestion is where you decide what ‘now’ means—and whether you can trust it when systems inevitably replay, lag, or change.”
The shift: from pipelines to time-aware contracts
The shift is simple: ingestion becomes contract-first and time-aware. Instead of treating streaming as automatically “better,” leading teams define ingestion by workload reality:
- Batch when the business tolerates delay and wants stability.
- Streaming when the business needs fast signals and can handle event-time complexity.
- CDC when the source-of-truth is operational and changes must be captured precisely (including updates and deletes).
The crucial move is that these aren’t just technology choices—they’re reliability promises. What counts as an authoritative record? What happens when a record arrives late? How are duplicates handled? Can you replay safely and get the same answer?
Why this trend exists
Four drivers are converging:
- AI and automation amplify ingestion flaws. Late events, duplicates, and silent schema drift don’t just skew dashboards—they create incorrect downstream actions and model behavior.
- Distributed systems reality became unavoidable. Replays, partial failures, and out-of-order events aren’t edge cases; they’re normal.
- Operational systems change constantly. Updates and deletes are business events; ignoring them breaks truth.
- Cost pressure punishes naive ingestion. “Just reload it” becomes financially unacceptable at scale; replay and incremental processing must be engineered.
What leading organizations build: Ingestion Control Planes
The winners implement an Ingestion Control Plane—not a tool, a design standard:
- Data contracts at the boundary: required fields, allowed schema evolution, semantic meaning, quality expectations, and ownership.
- Event-time semantics: explicit use of event time vs processing time, plus watermarking/allowed lateness policies.
- Idempotency by default: dedup keys, exactly-once effect (even if delivery isn’t), deterministic replays.
- Change capture discipline: clear handling for updates/deletes (not just inserts), with reconciliation rules.
- Quarantine, not contagion: bad data gets isolated with triage paths, rather than poisoning curated layers.
Business impact
- Cost and efficiency: fewer full reloads, cheaper backfills, reduced compute waste from reprocessing and “panic rebuilds.”
- Speed and adaptability: faster onboarding of sources and faster time-to-serve because contracts prevent downstream surprises.
- Risk, trust, and resilience: higher confidence in metrics and automation; fewer silent failures; controlled replay and recovery.
- Revenue or differentiation: reliable, timely signals enable better personalization, fraud detection, operational optimization, and AI features.
How leaders should respond (practical actions)
- Define ingestion SLAs/SLOs per domain (freshness, completeness, tolerated lateness)—and publish them like product guarantees.
- Standardize ingestion contracts (schema + semantics + ownership + compatibility rules + failure handling).
- Mandate idempotent replay behavior for all production-critical ingestion, including CDC.
- Classify sources by change type (append-only vs mutable vs high-delete) and choose patterns accordingly.
- Make quarantine and triage explicit (who owns the exception queue, resolution time targets, escalation rules).
Trend-specific CTA
Where does your enterprise still confuse “data arrived” with “data is true”—and what decisions are you making on that assumption?
CXO CTAs
- Institutionalize ingestion contracts as a production requirement: schema, semantics, ownership, and compatibility rules—no exceptions without time bounds.
- Make time semantics explicit: event time vs processing time, watermarking, late data policy, and replay guarantees.
- Require idempotent ingestion for critical domains: if re-run ≠ same outcome, it’s not production-grade.
Trend #2: Storage as Behavioral Lock-In — Lake, Warehouse, Lakehouse Becomes an Operating Choice
From 2026 through 2028, storage stops being a neutral “place to keep data” and becomes the strongest determinant of how your data organization behaves: how teams publish, how consumers query, how governance is enforced, how failures propagate, and how much you pay to get answers.
Anchor insight “The moment you write data, you’ve already chosen its future—governance, cost, and trust are downstream of storage behavior.”
The shift: from “cheap storage” to governed, workload-fit storage
The shift is that enterprises stop debating storage as ideology (“lake vs warehouse”) and start operating it as tiered, fit-for-purpose truth management:
- Raw capture optimized for fidelity and reprocessing (not consumption).
- Curated analytical truth optimized for consistency, concurrency, and stable semantics.
- Serving-ready datasets optimized for repeatability, performance, and controlled access patterns.
Instead of one big bucket or one giant warehouse schema, leading organizations treat storage as a portfolio with explicit rules for what belongs where, and why.
Why this trend exists
Four drivers are forcing discipline:
- Concurrency and mixed workloads are the norm. The same data is used for BI, ML features, ad hoc exploration, operational reporting, and AI workflows—each with different performance and governance needs.
- Schema drift and semi-structured data exploded. “Flexible” storage without controls becomes un-queryable, or worse, misleading.
- Cost is increasingly query-shaped, not storage-shaped. Scan-heavy patterns, recompute, and poor partitioning are what blow budgets.
- Trust is now audit-grade. Teams must prove provenance and enforce access/purpose—storage organization determines what is feasible.
What leading organizations build: Storage Tiers + Table Discipline
The winners implement storage tiering with explicit behavior:
- Bronze/Silver/Gold (or raw/curated/served) tiers with non-negotiable entry/exit criteria.
- Table design standards: partitioning strategy, clustering, compaction, file sizing, retention, and lifecycle.
- Immutable raw + governed curated: raw is append-only and replayable; curated is contract- and quality-controlled.
- Versioned datasets for reproducibility and safe backfills (you can re-run and explain changes).
- Access policy bound to tiers: raw is restricted; curated and served have controlled interfaces, not “everyone gets everything.”
This isn’t bureaucracy—it’s how you avoid the most common failure mode in modern data platforms: a lake that becomes a junk drawer or a warehouse that becomes a brittle bottleneck.
Business impact
- Cost and efficiency: lower scan/recompute costs, fewer emergency compactions, fewer “full reload” recoveries, predictable unit costs for core datasets.
- Speed and adaptability: faster onboarding when raw capture is standardized; faster consumption when curated data is stable and well-designed.
- Risk, trust, and resilience: fewer silent semantic errors; clearer lineage and evidence; safer backfills and reproducible reporting.
- Revenue or differentiation: reliable, performant datasets accelerate experimentation, personalization, pricing, supply chain optimization, and AI feature delivery.
How leaders should respond (practical actions)
- Adopt tiered storage with clear contracts: define what “raw,” “curated,” and “served” mean—and enforce it.
- Mandate table design standards (partitioning, retention, compaction, clustering) for production datasets.
- Treat raw as replayable evidence and curated as governed truth—don’t blur the two.
- Implement dataset versioning for critical domains so changes are explainable and reversible.
- Separate access from storage: serve governed products (semantic layer/APIs) instead of granting wide raw-table access.
Trend-specific CTA
Where are you relying on “storage is cheap” to excuse disorder—and what’s the downstream cost of mistrust and rework?
CXO CTAs
- Make tiering non-negotiable: raw/curated/served with entry gates, owners, and exit criteria.
- Institutionalize table discipline: partitioning + retention + compaction standards tied to cost and performance metrics.
- Stop granting broad raw access: publish governed interfaces and hold teams accountable to consumption contracts.
Trend #3: Transformation as State Management — Incremental-by-Default Becomes the Standard
From 2026 through 2028, transformation stops being “write SQL to shape data” and becomes how you manage state, change, and replay without breaking truth. The old default—full refreshes, monolithic ETL jobs, and “we’ll just rebuild it”—collapses under scale, cost scrutiny, and real-time expectations. The new default is incremental, deterministic, and backfill-safe.
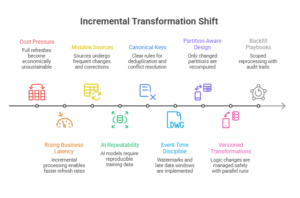
Anchor insight “Transformation is no longer a set of queries. It’s the control system that contains bad data, late data, and change—without rewriting history by accident.”
The shift: from full refresh pipelines to deterministic incremental systems
The shift is that transformation logic is engineered like production software:
- Incremental updates rather than reprocessing entire history.
- Deterministic outputs so replays produce the same answers.
- Explicit state handling for late-arriving records, corrections, and slowly changing dimensions.
- Backfills as a first-class motion—controlled, scoped, and auditable.
This is not a micro-optimization. It’s a fundamental change in reliability posture: you’re designing for the reality that data arrives late, sources correct themselves, and pipelines will be rerun.
Why this trend exists
Four drivers make incremental-by-default unavoidable:
- Cost pressure exposes “full refresh culture.” Full rebuilds become the fastest way to burn budgets and miss SLAs.
- Business latency expectations are rising. Incremental processing is what makes frequent refresh economically viable.
- Sources are mutable. Corrections, updates, deletes, and schema changes are normal, especially with CDC.
- AI requires repeatability. Feature sets, training data, and evaluation must be reproducible—or models become untrustworthy and hard to debug.
What leading organizations build: Controlled State + Reprocessing Mechanics
The winners implement a few non-negotiable mechanics:
- Canonical keys and merge semantics: clear rules for deduplication, upserts, deletes, and conflict resolution.
- Event-time vs processing-time discipline: watermarks, late data windows, and reconciliation policies.
- Partition-aware incremental design: only recompute what changed; isolate blast radius.
- Versioned transformations: when logic changes, you can run side-by-side, compare, and cut over safely.
- Backfill playbooks: scoped reprocessing with audit trails, consumer notifications, and rollback paths.
They also draw a hard line between correction and mutation: what changes historical truth, what creates a new version of truth, and what must be explainable.
Business impact
- Cost and efficiency: reduces compute waste from recomputation; makes backfills and fixes predictable and cheap.
- Speed and adaptability: teams ship changes without fearing full rebuilds; lower cycle times for new datasets and metrics.
- Risk, trust, and resilience: fewer incidents caused by accidental history rewrites; replay becomes safe; audits become defensible.
- Revenue or differentiation: faster reliable insights and features—especially where decisions depend on recent signals and corrected history (pricing, risk, personalization, ops).
How leaders should respond (practical actions)
- Mandate incremental-by-default for production datasets with documented exceptions (and expiration dates).
- Standardize merge and dedup semantics (keys, ordering rules, deletes) for each domain.
- Treat backfills as a controlled product motion: plan, scope, communicate, execute, validate, and rollback if needed.
- Require deterministic replay tests for critical transformations (same inputs → same outputs).
- Introduce versioned transformations for high-impact logic changes with parallel runs and reconciliation checks.
Trend-specific CTA
If you replay last week’s data, do you get the same answers—or a different reality that no one can explain?
CXO CTAs
- Kill “full refresh” as the default: require incremental patterns and enforce compute accountability.
- Make backfills governable: owners, timelines, consumer communication, and audit trails.
- Institutionalize determinism: replayability is a trust requirement, not a nice-to-have.
Trend #4: Orchestration as System Policy — DAGs + Events, With Governed Reruns and Dependency Discipline
From 2026 through 2028, orchestration stops being “a scheduler that runs jobs” and becomes the operating policy of your data system: when work triggers, how dependencies are enforced, how failures are contained, and how reprocessing happens without chaos. Most enterprises already have orchestration—but it’s often brittle: calendar-driven runs, hidden coupling, ad hoc backfills, and silent partial failures that leave consumers guessing.
Anchor insight “Orchestration isn’t scheduling. It’s how your enterprise decides what is allowed to run, when it’s allowed to run, and how it recovers without corrupting truth.”
The shift: from calendar-driven pipelines to hybrid, state-aware orchestration
The shift is that orchestration becomes hybrid by design:
- DAG orchestration for determinism, traceability, and reproducible runs.
- Event-driven triggers for responsiveness (data arrival, CDC changes, upstream completion, anomaly detection).
- State-aware execution that understands partitions, watermarks, and incremental boundaries—so the system runs only what changed.
Leading teams stop treating “daily at 2 AM” as a strategy and start treating orchestration as a set of explicit policies: dependencies, retries, replays, and consumer-ready guarantees.
Why this trend exists
Four drivers make this unavoidable:
- Upstream volatility is now normal. Sources arrive late, change frequently, and correct history. Schedules alone cannot represent reality.
- Backfills are frequent and expensive. Without governed reprocessing, teams create outages with “just rerun it.”
- Multi-system pipelines dominate. Orchestration must coordinate across ingestion, transformation, quality gates, and serving—not just “run SQL.”
- Consumers demand predictability. Users care about “is it ready and trustworthy?” not “did the job succeed?”
What leading organizations build: An Orchestration Control Plane
The winners implement orchestration as a control plane with four non-negotiables:
- Dependency truth, not implied coupling: every dataset has explicit upstream dependencies and readiness criteria.
- Rerun/backfill as first-class workflows: parameterized, scoped, auditable, and reversible—no heroic scripts.
- Quality gates inside the DAG: promotion from raw → curated → served is conditional, not assumed.
- Lineage-aware impact: when something fails or changes, you can see which downstream assets are impacted and how far the blast radius goes.
Most importantly, they separate execution from readiness: a job “success” does not automatically mean the dataset is valid for consumers.
Business impact
- Cost and efficiency: fewer wasteful runs; less recomputation; fewer emergency backfills that burn compute and people time.
- Speed and adaptability: event-triggered updates cut latency without turning everything into streaming complexity.
- Risk, trust, and resilience: fewer silent partial updates; consistent recovery semantics; reduced “data is wrong, but nobody knows why.”
- Revenue or differentiation: faster reliable signals power better operational decisions, personalization, fraud/risk controls, and AI features.
How leaders should respond (practical actions)
- Define dataset readiness explicitly (freshness + quality + completeness + lineage checks) and make “ready” a surfaced state.
- Adopt hybrid orchestration patterns: use DAGs for determinism and events for arrival-driven execution.
- Standardize backfill mechanics: parameterized runs, scoped partitions, approval gates for high-impact domains, audit trails.
- Build “promotion gates” between tiers so bad data cannot automatically reach curated/served layers.
- Instrument orchestration with lineage impact so incident response is measured in minutes, not days.
Trend-specific CTA
When data is wrong, can you answer—within minutes—what changed, what’s impacted, and what the safe rollback/replay path is?
CXO CTAs
- Make readiness a platform primitive: “job succeeded” is not a consumer guarantee; “dataset ready” is.
- Institutionalize governed backfills: no production reruns without scoped parameters, owners, and audit trails.
- Shift from schedules to signals: treat events (arrival, anomaly, correction) as first-class triggers where it reduces latency and waste.
Trend #5: Data Reliability Engineering — Idempotency, Replays, and Failure Modes Become Design Requirements
From 2026 through 2028, reliability stops being something you “add later” and becomes the core design constraint for data systems. In mature enterprises, the majority of data incidents aren’t caused by exotic bugs—they come from predictable realities: retries that duplicate records, partial failures that publish incomplete datasets, upstream corrections that invalidate downstream truth, and backfills that unintentionally rewrite history.
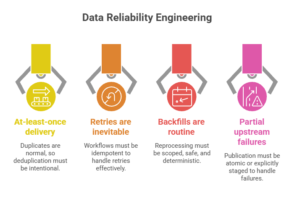
Anchor insight “A pipeline that ‘usually works’ is not production-grade. Production-grade means it behaves correctly under retries, duplication, partial failure, and replay.”
The shift: from “happy-path pipelines” to failure-aware systems
The shift is simple: teams stop optimizing for the happy path and start engineering for the conditions that happen every week:
- At-least-once delivery is normal → duplicates are normal → dedup must be intentional.
- Retries are inevitable → workflows must be idempotent.
- Backfills are routine → reprocessing must be scoped, safe, and deterministic.
- Partial upstream failures occur → publication must be atomic or explicitly staged.
This is where many organizations get stuck: they have tooling, but they don’t have reliability semantics. Reliability is not “more alerts.” It’s the discipline of predictable behavior.
Why this trend exists
Four drivers are making reliability non-negotiable:
- Decision automation magnifies errors. Bad data can trigger bad actions, not just wrong reports.
- Complexity exploded. More sources, more consumers, more transformations means more places for silent corruption.
- Reprocessing is now constant. Late data, CDC corrections, and logic changes force backfills as a standard operating motion.
- Trust is now an executive KPI. If leaders can’t trust numbers, they slow decisions, add manual controls, and lose speed.
What leading organizations build: Reliability Patterns as Platform Defaults
The winners bake these patterns in as defaults:
- Idempotent writes and “exactly-once effect”: even if ingestion is at-least-once, outputs converge to one correct result.
- Deduplication strategy by domain: event IDs, natural keys, ordering rules, and conflict resolution are explicit.
- Dead-letter queues (DLQs) + quarantine stores: bad records don’t crash systems; they route to triage with owners and SLAs.
- Atomic publish / staged promotion: datasets are produced in a staging area and promoted only when complete + validated.
- Backpressure and rate controls: upstream bursts don’t overwhelm downstream compute or violate freshness SLOs.
- Replay-safe checkpoints: you can re-run partitions/windows without contaminating downstream truth.
Most importantly, leading teams treat reliability as a shared contract: producers, platform, and consumers agree on replay and correction semantics.
Business impact
- Cost and efficiency: fewer incident fire drills; fewer expensive “rebuild everything” recoveries; reduced waste from reruns and duplicated compute.
- Speed and adaptability: safer changes to logic and sources; faster recovery when something breaks; faster delivery because teams trust the platform.
- Risk, trust, and resilience: fewer silent corruption events; controlled blast radius; audit-ready explainability for incidents and corrections.
- Revenue or differentiation: reliable data powers better operational outcomes—fraud prevention, personalization, supply chain decisions, AI feature freshness.
How leaders should respond (practical actions)
- Mandate idempotency for production pipelines (especially ingestion + curated layer). Make it a release gate.
- Implement DLQs/quarantine with ownership: define who triages, within what time, and how resolution feeds root cause fixes.
- Adopt atomic publish patterns: staging → validation → promotion; never “partially publish” without an explicit “incomplete” state.
- Standardize replay/backfill playbooks: scoped windows, approval gates for high-impact domains, consumer notifications, validation checks.
- Run post-incident loops that change design: every incident must produce a permanent reliability improvement, not just a patch.
Trend-specific CTA
If your top three datasets were replayed tomorrow due to an upstream correction, would they converge to the same truth—or create a new set of numbers and a new round of meetings?
CXO CTAs
- Make idempotency and replay safety non-negotiable for critical data products—treat them like financial controls.
- Operationalize DLQ ownership: exceptions must have named owners and resolution SLAs, not “someone will look.”
- Require atomic publishing: “ready” must be a promoted state, not an assumption.
Trend #6: Quality Moves to the Boundary — Validation Becomes a Control System, Not a Report
From 2026 through 2028, data quality stops being a downstream reconciliation exercise and becomes a boundary control system: detect defects at the moment data crosses a trust boundary, decide what happens next, and prevent bad data from silently contaminating everything downstream.
Most enterprises already “measure quality,” but too often it’s passive: dashboards, sampling, and after-the-fact firefighting. The new standard is active: quality gates tied to promotion, serving, and reliability SLOs.
Anchor insight “Quality isn’t a dashboard metric. It’s an enforcement mechanism—deciding what is allowed to become truth.”
The shift: from monitoring quality to enforcing quality
The shift is that quality becomes policy + execution, with explicit decisions:
- Reject: data is invalid and must not enter the system.
- Quarantine: data is suspicious or incomplete; isolate it with triage ownership.
- Warn: data is acceptable but degraded; publish with known limitations and consumer signaling.
This turns quality from an aspirational KPI into an operational control loop that reduces downstream blast radius.
Why this trend exists
Four forces are driving boundary-first quality:
- AI amplifies small defects into big outcomes. Training data drift, feature leakage, and silent null inflation can materially change model behavior.
- Self-serve consumption increases the surface area. More consumers means defects spread faster and get interpreted in more ways.
- Regulatory and audit expectations are rising. “We discovered it later” is not an acceptable control posture for many domains.
- Cost pressure punishes late detection. Fixing errors after transformation and serving multiplies reprocessing cost and human effort.
What leading organizations build: Quality Gates + Data SLOs
The winners build quality into the pipeline lifecycle:
- Ingress validation: schema validity, required fields, domain constraints, referential checks (where feasible), and reasonableness tests.
- Tier-to-tier promotion gates: raw → curated → served only happens when quality thresholds are met (or explicitly waived with an owner and expiry).
- Data SLOs for business-critical datasets: freshness, completeness, validity rates, duplication rates, drift indicators.
- Consumer signaling: datasets can be ready, degraded, or blocked—and consumers can see why.
- Exception operations: quarantines have queues, owners, SLAs, and root-cause workflows—not “somebody should look.”
The key design choice is to stop treating quality as a single score and treat it as fit-for-purpose constraints per domain. Finance data and clickstream data do not need the same quality gate—but both need explicit rules.
Business impact
- Cost and efficiency: fewer downstream rebuilds, fewer expensive backfills, less time lost to reconciliation and stakeholder escalations.
- Speed and adaptability: teams ship faster because defects are caught early and handled consistently, not discovered late via consumers.
- Risk, trust, and resilience: reduced likelihood of silent corruption; clearer audit posture; safer automation and AI use.
- Revenue or differentiation: trustworthy data improves conversion optimization, pricing, fraud controls, and AI feature reliability.
How leaders should respond (practical actions)
- Define “reject/quarantine/warn” policies per domain and make them enforceable at ingestion and promotion points.
- Create dataset-level SLOs for the top 20 data products and tie them to operational ownership (not just platform teams).
- Institutionalize promotion gates: curated and served layers require passing checks—or a time-bound, owned exception.
- Build an exceptions operating model: quarantine queues, triage SLAs, root-cause fixes, and recurring defect prevention.
- Connect quality metrics to business outcomes (missed orders, false fraud flags, model drift, reporting errors) so investment decisions are rational.
Trend-specific CTA
Where are you still “measuring quality” after the business has already consumed the data—and what is that delay costing you?
CXO CTAs
- Make quality gates mandatory at trust boundaries (ingress and tier promotion), not optional checks at the end.
- Demand dataset SLOs for critical domains—freshness, completeness, validity—and review them like operational KPIs.
- Fund exception operations: quarantines need owners and SLAs, or they become silent debt.
Trend #7: Schema Evolution as Compatibility Engineering — Versioning Becomes a Trust Mechanism
From 2026 through 2028, schema evolution stops being an annoying engineering detail and becomes a core reliability capability. As more domains publish data products and more teams consume them, breakages caused by “small” upstream changes become one of the most common sources of data incidents, rework, and mistrust.
The old posture—freeze schemas or let them drift—fails at scale. The new posture is explicit: schemas evolve, but compatibility is engineered.
Anchor insight “Schemas will change. The differentiator is whether change is governable—or whether consumers discover it in production.”
The shift: from “schema enforcement” to “schema compatibility”
The shift is that teams move from simplistic rules (“strict schema” vs “schema-on-read”) to a compatibility model:
- Contracts define semantics (not just columns): what fields mean, which are required, and what defaults imply.
- Versioning is explicit: consumers know what they’re getting and can plan upgrades.
- Deprecation is managed: fields don’t disappear overnight; they sunset on a schedule.
- Evolution is automated: schema diffs and compatibility checks run in CI/CD—not in Slack after an outage.
This is not bureaucracy. It’s how you scale data sharing without turning every release into a coordination crisis.
Why this trend exists
Four drivers are pushing this to the top:
- Domain-oriented data products increased change velocity. More producers means more independent releases—and more opportunity for accidental breaking changes.
- Semi-structured data is everywhere. Nested fields evolve rapidly, and “optional” becomes “required” without anyone noticing.
- AI and feature stores demand stability. Training and inference pipelines must receive consistent shapes—or drift becomes untraceable.
- Audit and governance expectations rise. If you can’t prove what version of data/logic produced an outcome, you can’t defend it.
What leading organizations build: Schema Governance Without Friction
The winners implement a lightweight but strict compatibility system:
- Compatibility rules by tier:
- Schema registries + CI checks: producers can’t ship incompatible changes without an explicit version increment and migration plan.
- Default handling and null discipline: explicit defaults and “unknown” semantics prevent silent logic changes.
- Deprecation workflows: owners, timelines, consumer comms, and automated warnings.
- Consumer protection: pinned versions for critical consumers; safe upgrade paths; parallel runs when needed.
The key move is to treat schemas the way mature engineering teams treat APIs: versioned, documented, tested, and deprecated—never “surprised.”
Business impact
- Cost and efficiency: fewer pipeline breakages, fewer emergency fixes, fewer cross-team coordination tax cycles.
- Speed and adaptability: teams ship changes faster because compatibility is tested automatically and consumers have stable contracts.
- Risk, trust, and resilience: fewer silent misinterpretations (the most dangerous failures); better auditability and reproducibility.
- Revenue or differentiation: faster iteration on data products, features, and models without destabilizing downstream consumers.
How leaders should respond (practical actions)
- Treat critical datasets as APIs: publish contracts (schema + semantics), owners, and compatibility guarantees.
- Adopt versioning rules: backward-compatible changes are allowed; breaking changes require new versions with migration windows.
- Automate schema diff + compatibility checks in deployment pipelines—no manual policing.
- Institutionalize deprecation: documented timelines, consumer notifications, and enforced removals only after expiry.
- Require replayability across versions for regulated or high-impact domains: be able to reproduce outputs from historical versions.
Trend-specific CTA
How many downstream teams are currently “coupled” to your schemas without realizing it—and what would break if a single upstream field changed tomorrow?
CXO CTAs
- Mandate contract + versioning for top-tier datasets: no unversioned breaking changes in production.
- Fund automated compatibility enforcement: schema diff checks in CI/CD are cheaper than repeated outages.
- Make deprecation a discipline: define migration windows, enforce ownership, and remove dead fields intentionally.
Trend #8: Serving as a Product Layer — Semantic Consistency Becomes the Last-Mile Differentiator
From 2026 through 2028, the center of gravity shifts from “can we produce datasets?” to “can we reliably serve meaning?” Most data platforms fail at the last mile: teams technically have access to data, but they don’t share definitions, don’t trust metrics, and rebuild the same logic in every dashboard, feature pipeline, and report. The result is predictable: duplicated effort, inconsistent KPIs, and decision drag.
Anchor insight “If the enterprise can’t agree on meaning at the point of consumption, every upstream investment turns into downstream confusion.”
The shift: from tables as outputs to products as interfaces
The shift is that organizations stop treating tables as the product and start treating interfaces as the product:
- Semantic layers for human consumption (metrics, dimensions, definitions, guardrails).
- Data APIs and feature interfaces for application and ML consumption (stable contracts, versioning, latency expectations).
- Consumption contracts that specify what’s guaranteed (freshness, grain, known limitations, deprecation timelines).
Serving becomes a discipline of stable meaning, not just performant queries.
Why this trend exists
Four drivers are accelerating the shift:
- Self-serve scaled consumption—but also scaled inconsistency. More users means more definitions unless semantics are centralized and governed.
- AI and applications consume data continuously. They need stable contracts and predictable latency, not “whatever the latest table looks like.”
- Executive trust is fragile. KPI disputes and metric drift slow decisions and create shadow reporting.
- Data products are now cross-domain. Business outcomes require combining domains (customer, product, finance, operations)—semantic alignment becomes the bottleneck.
What leading organizations build: A Serving Layer With Contracts
The winners operationalize serving with a few non-negotiables:
- Metric governance as a product: canonical definitions (e.g., revenue, active user), owned by named accountable leaders, with change control.
- A semantic layer that’s actually enforced: consistent metric logic and access controls used across BI, notebooks, and downstream services.
- Stable, versioned interfaces: API-like contracts for high-value datasets and features, including backward compatibility rules.
- Consumer-aware publishing: datasets have declared grain, latency expectations, and “ready/degraded” states.
- Experience design for consumption: discovery, documentation, examples, and guardrails—because adoption without comprehension is just confusion at scale.
The key is that “serving” is not a final step after engineering—it’s the system by which value is realized and trust is preserved.
Business impact
- Cost and efficiency: less duplicated logic, fewer reconciliation meetings, fewer conflicting dashboards, lower rework across teams.
- Speed and adaptability: faster experimentation and rollout because teams consume stable interfaces rather than reverse-engineering tables.
- Risk, trust, and resilience: fewer KPI disputes, better auditability of metrics, controlled changes with visibility to impacted consumers.
- Revenue or differentiation: consistent metrics improve pricing, growth loops, and operational optimization; stable feature interfaces improve AI and personalization reliability.
How leaders should respond (practical actions)
- Identify the top 20 enterprise metrics and certify them with owners, definitions, and change-control policies.
- Implement a semantic serving layer that’s used across BI and programmatic consumers—not an optional “nice-to-have.”
- Publish contract-first data products: declared grain, freshness targets, quality SLOs, and versioning rules.
- Shift access from “raw tables” to “governed interfaces” where possible: semantic views, APIs, and curated feature sets.
- Measure adoption + trust: time-to-find, time-to-use correctly, metric dispute rate, and consumer satisfaction.
Trend-specific CTA
Where is your organization still “shipping tables” and assuming consumers will figure out meaning—and what decisions are being made on inconsistent definitions today?
CXO CTAs
- Treat metrics as enterprise assets: certify critical KPIs with ownership, definitions, and change control.
- Make serving contract-first: grain, freshness, quality, and versioning are part of the product—not tribal knowledge.
- Reduce raw-table sprawl: shift consumption toward governed interfaces and semantic consistency.
Trend #9: Performance Becomes Cost Control — Workload Shaping Replaces “Just Add Compute”
From 2026 through 2028, performance stops being a technical tuning exercise and becomes a first-order financial control. In modern data platforms, the biggest cost drivers are rarely storage—they’re scan behavior, recomputation, concurrency, inefficient joins, uncontrolled backfills, and “every team runs the same query slightly differently.”
Elasticity didn’t solve performance. It just made inefficiency easier to scale.
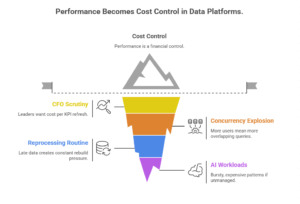
Anchor insight “In data platforms, performance is unit economics. If queries aren’t shaped, costs aren’t governable.”
The shift: from reactive tuning to designed workload economics
The shift is that enterprises move from ad hoc optimization (“this dashboard is slow—add clusters”) to workload shaping:
- Design tables to match access patterns (partitioning, clustering, compaction).
- Reduce repeated scans with caching and pre-aggregation where it’s economically justified.
- Control concurrency and “noisy neighbor” behavior with quotas and workload isolation.
- Engineer backfills and incremental compute so reprocessing doesn’t become a budget event.
This becomes a product discipline: performance targets are tied to business outcomes, and cost is attributable to consumers.
Why this trend exists
Four drivers are forcing the issue:
- CFO scrutiny and unit-cost thinking are rising. Leaders want cost per KPI refresh, per dashboard view, per feature pipeline, per model update.
- Concurrency exploded with self-serve. More users and tools means more simultaneous, overlapping queries.
- Reprocessing became routine. Late data, CDC corrections, and logic changes create constant backfills and rebuild pressure.
- AI workloads increase variance. Feature extraction, embedding generation, and evaluation workloads create bursty, expensive patterns if unmanaged.
What leading organizations build: A Performance & Cost Control Plane
The winners put in place repeatable performance patterns:
- Table discipline as policy: partitioning strategy, clustering keys, file sizing/compaction, retention, and statistics upkeep.
- Precompute with intent: materialized views / aggregates where they reduce total scan cost and stabilize latency.
- Caching with freshness rules: cache isn’t “hope”; it’s an explicit trade-off with declared staleness tolerance.
- Workload isolation + quotas: separate ad hoc exploration from production serving; prevent runaway queries.
- Cost attribution by consumer: tie spend to teams, products, and workloads so optimization conversations are grounded.
- Backfill throttling and guardrails: rate limits, windowing, and approval gates for expensive recomputation.
The key move is treating “fast enough” and “cheap enough” as designed properties—not incident responses.
Business impact
- Cost and efficiency: lower scan/recompute bills, reduced surprise spend, better commitment utilization, fewer emergency scale-ups.
- Speed and adaptability: predictable performance enables confident releases and faster experimentation without fear of blowing budgets.
- Risk, trust, and resilience: fewer outages from overload; controlled backfills reduce operational instability.
- Revenue or differentiation: better customer and decision latency; more reliable AI feature refresh cycles; improved operational responsiveness.
How leaders should respond (practical actions)
- Define performance SLOs for critical consumption paths (dashboards, APIs, feature pipelines) and treat breaches as incidents.
- Standardize table design patterns by domain (partitioning, clustering, compaction, retention) and enforce them at promotion.
- Implement workload isolation and guardrails: quotas, concurrency controls, and “safe defaults” for ad hoc usage.
- Adopt cost attribution and showback tied to datasets and consumers—then optimize the top 10 cost drivers, not everything.
- Govern backfills: throttle, window, and require scoped plans for high-cost recomputation.
Trend-specific CTA
Which 10 queries, dashboards, or pipelines are quietly driving the majority of your platform spend—and who owns fixing their shape?
CXO CTAs
- Make unit-cost visible: cost per dataset, per dashboard, per model refresh—tie spend to consumption and owners.
- Institutionalize workload shaping: enforce table discipline and caching/precompute strategies where they reduce total cost.
- Control recomputation: backfills and rebuilds must be planned, throttled, and auditable—never “run it and hope.”
Trend #10: Observability & Data SLOs — From “Pipeline Green” to “Business-Ready and Defensible”
From 2026 through 2028, observability stops being “logs and alerts for jobs” and becomes a reliability system for truth. In mature enterprises, the most damaging failures aren’t hard outages—they’re silent degradations: freshness slips, completeness drops, duplication spikes, drift creeps in, and consumers keep using the data anyway. The platform looks healthy. The business is flying blind.
Anchor insight “A pipeline can be up while the business is wrong. Observability must be data-aware, consumer-aware, and SLO-driven.”
The shift: from job monitoring to data reliability operations
The shift is that organizations move from “did the DAG succeed?” to “is the dataset fit for purpose right now?” That means:
- Dataset-level SLOs, not just pipeline SLAs: freshness, completeness, validity rates, duplication, drift indicators.
- Lineage-aware impact analysis: when something breaks or degrades, you immediately know who and what is impacted.
- Readiness states: Ready / Degraded / Blocked—with clear reasons and timestamps.
- Incident loops that change design: observability doesn’t just notify; it drives corrective action and prevention.
This is where many teams get trapped: they build dashboards for the platform team, but not operating loops for the business.
Why this trend exists
Four forces make this inevitable:
- Data is now operational. It drives workflows and AI systems; silent errors become active business harm.
- The dependency graph is too complex for intuition. Hundreds of upstream/downstream links require automated impact reasoning.
- Self-serve amplifies blast radius. One degraded dataset can quietly affect dozens of dashboards and models.
- Audit expectations are rising. Organizations must show when data changed, why, and what controls responded.
What leading organizations build: The Data Reliability Control Loop
The winners operationalize observability as a closed loop:
- Measure: automated checks for freshness, volume/completeness, validity, duplicate rate, distribution/drift, schema evolution events.
- Detect: anomaly detection with thresholds tied to business tolerance (not arbitrary “5%”).
- Diagnose: lineage + run metadata + change logs to explain what changed and where it propagated.
- Respond: workflow-based actions—quarantine, rollback/pin version, trigger targeted backfill, notify consumers, open incident with context.
- Improve: postmortems that modify contracts, gates, and reliability patterns so the same class of failure doesn’t recur.
Critically, top teams do not try to observe everything equally. They start with crown-jewel datasets and consumption paths.
Business impact
- Cost and efficiency: fewer long investigations, fewer “war rooms,” less wasted compute from blind reruns; faster MTTR.
- Speed and adaptability: teams can change pipelines and logic faster because failures are detected early and scoped precisely.
- Risk, trust, and resilience: fewer silent corruptions; defensible reporting; stronger audit posture and incident evidence.
- Revenue or differentiation: reliable data keeps growth and ops loops stable—pricing, fraud, personalization, supply chain, AI features.
How leaders should respond (practical actions)
- Define Data SLOs for the top 20 datasets: freshness, completeness, validity, duplication, drift—owned by named teams.
- Implement readiness states for critical data products: Ready/Degraded/Blocked with clear consumer visibility.
- Make lineage operational: impact analysis must be part of incident response, not a documentation artifact.
- Automate responses via workflows: quarantine, rollback/pin, targeted backfill, consumer notifications—auditable and reversible.
- Run data postmortems like software postmortems: each incident produces a permanent design/control improvement.
Trend-specific CTA
When a critical metric is wrong, can you identify the root cause and the impacted consumers within minutes—and prove exactly when the error began?
CXO CTAs
- Shift the KPI from “job success” to “dataset reliability”: SLOs tied to business tolerance.
- Operationalize lineage: impact analysis must be embedded in incident workflows.
- Fund Data Reliability Engineering as a capability: not more dashboards—closed loops that detect, diagnose, and act.
Trend #11: Security & Privacy-by-Design — Policy Becomes an Execution Boundary, Not a Review Step
From 2026 through 2028, data security stops being “access control + periodic audits” and becomes continuous, enforceable policy across the data lifecycle—ingestion, storage, transformation, serving, and AI usage. The driver is straightforward: data products are being shared more broadly (self-serve, partners, AI systems), while regulatory expectations and breach consequences continue to rise. Security and privacy can’t remain a last-mile checklist.
Anchor insight “Security and privacy aren’t layers you add. They’re boundaries that determine what data is allowed to exist, move, and be used—by design.”
The shift: from perimeter controls to purpose-bound data access
The shift is that organizations move from “who can access this table?” to “who can use this data for what purpose, under what constraints, and with what evidence?” That includes:
- Policy as code enforced automatically, not interpreted manually.
- Purpose limitation and minimization (collect less, retain less, expose less).
- Attribute-based access controls (based on user role + data sensitivity + context).
- Safe data sharing patterns (masked views, tokenization, row/column controls, differential access).
- AI-era controls (preventing sensitive leakage into prompts, training sets, and retrieval indexes).
Why this trend exists
Four forces are driving security/privacy into the engineering core:
- Data sharing scaled faster than governance. Self-serve and cross-domain use create uncontrolled exposure unless policy is systematic.
- Regulation is getting operational. Expectations increasingly focus on demonstrable controls: retention, purpose, minimization, audit trails.
- AI expands the exfiltration surface. RAG, embeddings, and training workflows can unintentionally repackage sensitive data.
- Incident response requires precision. You need to know exactly what data was accessed, by whom, when, and how it flowed.
What leading organizations build: A Data Policy Control Plane
The winners implement a policy control plane that travels with data:
- Classification at ingestion: sensitivity tags and handling rules applied when data enters the platform.
- Fine-grained access controls: row/column-level rules bound to identity and context.
- Data minimization by default: only the necessary fields reach curated/served layers; sensitive raw access is restricted.
- Retention and deletion enforcement: lifecycle rules are automatic, provable, and consistent across copies/derivatives.
- Auditable usage evidence: access logs + lineage = defensible answers during audits and incidents.
- AI guardrails: block sensitive fields from retrieval indexes; enforce “no-train/no-export” rules; validate prompts and outputs for leakage risk.
This isn’t “security slowing teams down.” Done right, it accelerates delivery by removing case-by-case negotiation and making safe paths the default.
Business impact
- Cost and efficiency: fewer manual access reviews, fewer audit scrambles, less rework to remediate uncontrolled sharing.
- Speed and adaptability: teams move faster when policies are pre-defined and enforced automatically.
- Risk, trust, and resilience: reduced breach likelihood and blast radius; stronger auditability; clearer accountability.
- Revenue or differentiation: enables trusted data sharing with partners and safer AI adoption—without freezing innovation.
How leaders should respond (practical actions)
- Define enterprise data handling tiers (public/internal/confidential/restricted) with default controls and evidence expectations.
- Enforce classification at ingestion and propagate tags through transformations and serving.
- Adopt purpose-bound access patterns for sensitive domains (who can use what data for what use case).
- Automate retention and deletion across raw/curated/served—including derived datasets and feature stores.
- Establish AI-era data guardrails: prevent sensitive data from entering prompts, training corpora, and retrieval indexes by default.
Trend-specific CTA
Where is sensitive data currently “governed by policy docs” rather than governed by enforceable controls—and what would you have to prove in an audit tomorrow?
CXO CTAs
- Make policy executable: policy-as-code with automated enforcement and audit trails.
- Mandate minimization: stop promoting sensitive fields unless a named use case requires them.
- Secure AI data flows now: treat retrieval/training pathways as high-risk data sharing channels with explicit controls.
Trend #12: Contract-First Data Products — Interfaces Replace Tables, Ownership Replaces Central Policing
From 2026 through 2028, the defining move in data engineering is that datasets stop being “things you query” and become products you depend on—with explicit interfaces, guarantees, and accountable owners. This is the only scalable response to the explosion of producers, consumers, and use cases (analytics, operations, AI, partners). Without contracts, every consumption is reverse engineering—and every change becomes a coordination tax.
Anchor insight “If data isn’t a product with a contract, every consumer becomes an unpaid QA team—and every producer change becomes a production incident.”
The shift: from shared tables to governed interfaces
The shift is that the enterprise moves from table-centric sharing to interface-centric delivery:
- A data product has a clear purpose, defined consumers, and declared guarantees.
- The “interface” can be a governed table, semantic model, API, or feature set—but it is stable, versioned, and documented.
- Ownership is explicit: one team is accountable for reliability, change management, and consumer outcomes.
This is where many enterprises misread the moment: they try to scale self-serve by expanding access. Contract-first data products scale self-serve by expanding clarity.
Why this trend exists
Four drivers are converging:
- Domain scale broke centralized governance. A central team can’t review every schema change, metric definition, and exception.
- AI and automation need predictable inputs. Models and agents fail silently when interfaces drift or semantics are unclear.
- Regulatory and audit pressure demands accountability. “It’s in the lake” isn’t a control. Someone must own the truth.
- Cost and quality are now consumer-shaped. Without contracts, consumption becomes unbounded—driving waste, duplication, and inconsistency.
What leading organizations build: A Data Product Operating Model
The winners implement an operating model with non-negotiables:
- Product contracts that specify:
- Ownership and on-call clarity: producers own reliability and consumer communication, not just production of data.
- Discoverability and documentation as part of “done.”
- Change management that looks like API management: compatibility rules, version bumps, migration windows, and consumer notifications.
- Scorecards that measure outcomes: adoption, trust, incident rate, SLO attainment, and cost-to-serve.
The best teams also treat “consumer experience” seriously: if it’s hard to find or use correctly, it will be reimplemented—badly.
Business impact
- Cost and efficiency: reduced duplicate pipelines, fewer conflicting definitions, fewer reconciliation cycles and ad hoc extracts.
- Speed and adaptability: teams build faster on stable interfaces; less coordination required for safe change.
- Risk, trust, and resilience: clearer accountability, audit-ready evidence, fewer silent breaks from upstream drift.
- Revenue or differentiation: faster reliable delivery of customer and operational insights; stronger AI feature and analytics velocity.
How leaders should respond (practical actions)
- Name “crown jewel” data products (top 20–50) and assign accountable product owners with reliability obligations.
- Standardize data product contracts (grain, semantics, SLOs, access policy, versioning) and make them release requirements.
- Introduce versioning + deprecation discipline like APIs: breaking changes require new versions and migration windows.
- Measure outcomes, not artifacts: adoption, trust, incident rate, cost-to-serve, and time-to-correct use.
- Limit raw-table sprawl: steer consumption toward governed interfaces (semantic models, APIs, curated products).
Trend-specific CTA
Which of your most critical datasets would still be trusted if the owning team changed tomorrow—and no one could explain its guarantees?
CXO CTAs
- Institutionalize contracts: no critical dataset without grain, semantics, SLOs, and versioning rules.
- Make ownership real: data products need accountable owners and consumer support paths.
- Shift from “access” to “interfaces”: self-serve scales on clarity and guarantees, not just permissions.
Closing Perspective — All-Up CTA (Conclusion)
Stop treating data engineering as a pipeline factory. In 2026, the competitive advantage is not “more data” or “more tools”—it’s operated truth: truth that is contract-defined, reliably produced under failure, economically sustainable, and defensible under audit.
Across these 12 trends, the convergence is clear:
- Truth is time-bound (ingestion semantics, CDC discipline, replay safety).
- Truth is tiered and intentional (raw evidence → curated governance → served meaning).
- Truth is operated like production (SLOs, observability loops, incident learning).
- Truth is consumed through interfaces (semantic consistency, contracts, versioning).
- Truth is constrained by economics and policy (workload shaping, unit costs, privacy/security boundaries).
What leaders must stop doing
- Stop “green job = healthy data.” Job success is not a consumer guarantee.
- Stop full-refresh and ad hoc backfill culture. It’s the most expensive form of uncertainty.
- Stop shipping tables and calling it self-serve. That scales confusion, not value.
- Stop relying on policy documents for control. If policy isn’t enforceable, it’s optional.
What leaders must commit to in the next 12 months
- Define contracts for your crown-jewel data products (grain, semantics, SLOs, versioning, access policy).
- Make reliability primitives default (idempotency, DLQs/quarantine, atomic publish, deterministic replay).
- Institutionalize data SLOs + readiness states (Ready/Degraded/Blocked) with lineage-aware impact.
- Treat performance as unit economics: cost per dataset/query/model refresh, owned and optimized.
- Embed security/privacy-by-design: classification at ingress, purpose-bound access, retention enforcement, AI guardrails.
What must be re-architected, not optimized
- The boundary between raw and trusted. Quality gates, promotion controls, and replay safety belong here.
- The serving layer. Stable semantics, certified metrics, and governed interfaces are where value is realized.
- The operating model. Ownership, on-call, incident loops, and change management must look like software.
Enterprise-level CTA: Pick your top 20 data products and run a hard assessment: Do they have contracts, SLOs, readiness states, replay safety, and accountable owners? If not, you don’t have a data platform—you have a dependency chain. Rebuild those 20 as the foundation, then scale.
Leave a Reply