Top Trends in Data, Analytics & Governance for 2026–2028

Data is entering a new phase inside the enterprise—not because we found a better place to store it, but because the way it is created, consumed, and governed has changed.
A decade ago, software ate the world. Now, workflows are eating data. Data used to be something you analyzed after the fact. Today it is being pulled into live processes—customer journeys, risk decisions, fulfillment, approvals—where the output isn’t a chart, it’s a decision and, increasingly, an action. Once agents enter the loop, the leadership question changes from “can we generate answers?” to: can we operate at speed with control—and prove it under pressure? As a rule of thumb: if you can’t show your work, you don’t get to ship at scale.
AI has quietly changed shape inside the enterprise. It started as a content machine. It’s becoming a decision machine—and, increasingly, an execution layer. The post-ChatGPT reality accelerated this shift by expanding what “enterprise data” even is. The explosion isn’t only rows in tables. It’s a growing universe of artifacts—documents, chats, tickets, code, audio/video transcripts—and the AI-derived layer wrapped around them: summaries, extracted entities, embeddings, prompts, synthetic variants, and AI exhaust. This isn’t just more volume. It’s more surface area—for value, for leakage, for inconsistency, and for audit.
Where most enterprises misread the moment is predictable:
1) They invest in AI capability, not decision credibility. The failure mode isn’t the LLM “hallucinating.” It’s your data reality: freshness gaps, unclear ownership, metric conflicts, hidden copies, missing lineage, and ungoverned context.
2) They treat governance as policy text, not runtime control. In an agentic world, “governance documents” don’t govern anything. Trust has to be enforceable—at ingestion, at query time, and at tool-use time.
3) They keep copying data like it’s harmless. In 2026–2028, every extra replica is a multiplier on exposure, inconsistency, and audit cost—especially when AI is consuming everything, including unstructured content.
Prediction: by 2028, most of the “decision context” enterprises rely on will originate in unstructured artifacts and AI-derived representations(summaries, embeddings, graph relationships), not in relational tables.
That’s the inflection point for 2026–2028. That’s why the constraints tightening around sovereignty, security posture, and auditability are moving upstream into architecture. If you can’t explain why a system produced an outcome or took an action—and demonstrate it was allowed—you don’t have scale. You have exposure.
The winners won’t be the companies with the most pilots or the most tools. They’ll be the ones that build operational truth: stable meaning across the enterprise, disciplined data movement, engineered reliability, and auditable decisions—so velocity rises without multiplying risk.
The 25 trends that follow are micro by design. Individually, each looks incremental. Together,
they describe the operating model required for this era: a data + AI operating system built for
reuse, control, and provable outcomes.Bottom line: 2026–2028 is the “operational truth” era. The winners won’t be the companies with the most AI pilots. They’ll be the ones that can consistently answer—and prove: What data was used, under what policy, with what quality, and who approved the resulting action?
Trend #1: GenAI Data Sprawl Governance — Taming the AI Content Explosion
From 2026 through 2028, the fastest-growing “data estate” in most companies won’t be lakehouses or warehouses—it will be AI artifacts: generated documents, meeting summaries, prompt libraries, embeddings, vector indexes, agent run logs, synthetic datasets, and the quiet trail of “AI data exhaust.” This sprawl will look harmless at first (“it’s just text”), until it becomes the untracked dependency behind customer responses, executive decisions, and automated actions.
The winners will treat AI artifacts like regulated enterprise assets: owned, classified, lifecycle-managed, and governed by allowed-use rules (allowed-to-train vs allowed-to-answer vs allowed-to-export). Everyone else will scale ambiguity—and then act surprised when trust collapses.

The shift is from governing datasets and dashboards to governing the full AI content lifecycle—including what gets generated, what gets reused, what gets embedded, and what gets promoted into “truth.”
Three forces converge here:
- AI data exhaust becomes “shadow data” at enterprise scale Copilots and agents create content everywhere—documents, chats, tickets, emails, code comments, knowledge bases. That output gets copied, pasted, re-embedded, and reused across teams. If it’s not tagged with provenance, confidence, and ownership, it becomes unmanageable fast.
- Artifact ownership + allowed-use becomes the new governance primitive Classic governance asks: “Who can access this table?” AI-era governance asks: “Who owns this prompt? This embedding index? This synthetic dataset? And what is it allowed to be used for?” Without explicit ownership and allowed-use policy, you’ll see prompt reuse without review, embeddings built from sensitive content, and synthetic data circulating without a validated-state.
- Contamination prevention becomes a reliability requirement, not a compliance add-on The most expensive failures won’t be dramatic breaches—they’ll be quiet contamination: unverified GenAI outputs being re-ingested into systems as “source truth,” regulated content leaking into embeddings, or stale artifacts powering confident answers. In an agentic world, that contamination doesn’t just misinform—it can trigger actions.
A practical Microsoft example: Azure/Microsoft 365-heavy enterprises can extend familiar governance patterns into AI interactions and AI artifacts. Microsoft Purview provides audit logs for Copilot and AI application interactions, so Copilot usage isn’t “invisible chat”—it’s auditable activity. And Microsoft Fabric governance integrates with Purview sensitivity labels—labels can be applied across Fabric items and admins can monitor sensitivity label activity via Purview Audit, which helps keep protection consistent as AI outputs move through analytics workflows.
Business impact: fewer “confidently wrong” decisions, lower rework, faster agent rollout with guardrails already in place, reduced leakage risk into embeddings, and stronger defensibility when stakeholders ask: “Why did the system answer that—and what did it use?”
CXO CTAs:
- Stand up an AI Asset Registry: treat prompts, embeddings, vector indexes, synthetic datasets, and agent workflows as governed assets with owners and lifecycle rules.
- Define allowed-use policies that can be enforced: allowed-to-train / allowed-to-embed / allowed-to-answer / allowed-to-export—then make violations blockable, not just reportable.
- Mandate provenance + confidence labeling for AI artifacts: freshness, source links, owner, and validation state—so reuse becomes safe and intentional.
- Implement contamination controls: prevent generated outputs from becoming “truth” without verification; segment regulated data from embedding pipelines unless explicitly approved.
- Make auditability a release gate: if an AI output can influence a decision or action, you must be able to reconstruct the chain of custody.
Trend #2: Data & Analytics Platforms with Agents / CoPilots — From Dashboards to Dialogue to Supervised Execution
From 2026 through 2028, analytics will stop being a place people go and become something work pulls in—as conversational agents sit inside Teams, CRM, ITSM, and finance systems. The defining shift won’t be prettier dashboards. It will be agentic BI: “ask in plain English → get an answer → generate a narrative → propose an action → execute under supervision.”

This is where many BI programs will either modernize fast—or quietly become irrelevant. Static KPI packs won’t survive in a world where leaders expect real-time “explain what changed,” “what should we do,” and “open the right ticket” in the same flow.
The shift is from analytics as reporting to analytics as a guided decision-and-action loop—with guardrails, approvals, and traceability.
Three forces converge here:

- Dashboard-to-dialog becomes the default user experience (“data vibing”) People won’t wait for a report refresh. They’ll ask: “What changed since last week and why?” and expect a contextual response, not a page of visuals. This pushes platforms toward conversational search across reports, semantic models, and governed agents—so business users can talk to data, not navigate it.
- Agentic BI moves from insight to “supervised execution” The real productivity unlock is not answering questions—it’s handling the next step: creating a Jira ticket, drafting a change request, generating a PR, emailing stakeholders, or triggering a workflow. But the enterprise requirement is equally clear: execution must be supervised (approval gates, role-based permissions, audit logs, and safe tool access). “Autonomous” becomes less important than “controlled.”
- BI modernization becomes an operating model problem (not a tools problem) As agents become the interface, BI needs:strong semantics (consistent definitions), trusted freshness/confidence signals, human-readable storytelling, and clear escalation paths when confidence is low. In practice, this becomes a maturity curve (what I call the “BI evolution ladder”): from static reporting → self-service → governed self-service → conversational insight → proactive insight → supervised action.
A practical Microsoft example: Microsoft is explicitly building toward this “ask-anything” and “agent surface” model. Copilot in Power BI supports a standalone, full-screen experience to find and analyze any report, semantic model, and Fabric data agent a user has access to. (Microsoft Learn) Copilot can also help create/edit report pages through natural language. (Microsoft Learn) On the governed-agent side, Microsoft Fabric data agents are designed to let teams build conversational Q&A over data stored in Fabric OneLake, making insights accessible via plain English. (Microsoft Learn) And Fabric data agents can be published into the Agent Store in Microsoft 365 Copilot (so users can interact from Teams) while respecting underlying data permissions like RLS/CLS. (Microsoft Learn) Why this matters: it shows where the market is going—analytics experiences that live where decisions happen, with governed access and reuse.
Business impact: faster time-to-insight (minutes, not days), fewer “analytics translation” cycles, higher adoption, and measurable productivity uplift as insights move into workflows. The downside—if unmanaged—is severe: inconsistent answers, metric chaos, tool misuse, and “shadow agents” operating outside governance.
CXO CTAs:
- Redesign BI around decisions, not reports: pick 5–10 high-value decisions and build conversational + narrative + action patterns around them.
- Institutionalize supervised execution: approvals, tool permissioning, and auditability must be part of the agent experience—not bolted on later.
- Mandate semantic clarity: one definition per metric, domain ownership, and change control—because agents amplify ambiguity.
- Introduce confidence UX: freshness, coverage, confidence, and owner labels should be visible in every answer to prevent “confidently wrong.”
Measure outcome, not engagement: track cycle time reduction, prevented escalations, faster closes, fewer rework loops—tie it to unit economics.
Trend #3: Data Contracts With Shift-Left Enforcement — Make Breakages Fail in CI, Not in Production
From 2026 through 2028, the biggest “hidden tax” in analytics and AI will be unannounced change: upstream schema drift, metric logic edits, new null behavior, and silent definition swaps. In an agentic world, that doesn’t just break dashboards—it breaks decisions and automated actions.
The shift is from “we’ll detect issues downstream” to producer–consumer contracts enforced upstream—so breaking changes fail fast, before they ship.
Three forces converge here:
- Producer–consumer accountability becomes non-negotiable Data products need explicit owners, versioning, and SLAs. If nobody “owns” the contract, everyone pays the incident cost.
- Contract tests move into CI/CD (shift-left) Teams will validate schema, constraints, freshness expectations, and metric definitions during build/deploy—turning runtime surprises into build failures. This “shift-left” framing (use CI pipelines + contract tests to block bad changes) is increasingly treated as the practical path to reliability at scale.
- AI amplifies the blast radius of ambiguity Agents don’t pause to debate definitions. If your metric semantics drift, the system will still answer—confidently. Contracts become the guardrail that keeps semantics stable and explainable.
A practical Microsoft example: Microsoft Fabric has the mechanics needed to operationalize shift-left patterns in analytics estates:
- Git integration to version and manage Fabric items with standard development workflows.
- Deployment pipelines to promote content through dev → test → prod stages.
- Guidance on CI/CD workflow options reinforces that teams can build structured release processes around Fabric content. Leadership takeaway: use these ALM primitives to attach contract checks to promotions—not to ship faster, but to ship safer.
Business impact: fewer metric disputes, fewer downstream incidents, lower on-call burden, faster releases with confidence, and significantly improved trust in AI answers that depend on stable semantics.
CXO CTAs:
- Mandate contracts for decision-grade data products: schema + constraints + freshness + semantic definitions + SLA/owner.
- Make breaking changes a governed event: versioning, impact analysis, and explicit approvals for contract changes.
- Shift-left enforcement as a release gate: contract tests must pass before dev→test→prod promotion.
- Track “contract breach rate” as an exec metric: if it’s rising, your reliability strategy is failing—regardless of how many dashboards look green.
Trend #4: Lakehouse 2.0 — Multi-Engine, Multimodal, Open Interoperability
From 2026 through 2028, the “lakehouse” stops being a storage pattern and becomes an interoperability contract. Enterprises will no longer tolerate a world where each analytics engine creates its own copy, its own semantics, and its own governance gaps. They will demand a data foundation where multiple engines (SQL, Spark, BI, ML/AI) can operate on one governed set of open data, spanning structured + unstructured + vector/graph, without turning integration into a permanent migration program.
The winners will treat the lakehouse as a multi-engine operating layer with open formats and portable governance. The laggards will keep paying the “replatform tax” every time a new engine, model, or modality becomes essential.
The shift is from lakehouse as “storage + compute convenience” to lakehouse as open, multimodal, governance-consistent interoperability—so engines can change without redoing the entire data estate.
Three forces converge here:
- Open formats become the enterprise’s exit strategy (and performance strategy) Open table/file formats (Delta/Parquet/Iceberg) and standard endpoints reduce lock-in and allow the same data to be used across engines without bespoke conversion projects. The practical implication: portability becomes a board-level risk reducer—because it limits supplier concentration and preserves negotiating leverage. Microsoft explicitly positions OneLake around openness (Parquet/Delta/Iceberg) to keep one copy accessible by multiple engines. (Microsoft)
- Multi-engine isn’t optional—it’s how AI + analytics actually runs A single engine won’t cover everything:
- BI needs fast semantic queries,
- data engineering needs Spark-scale transforms,
- AI needs vector + graph + search,
- finance needs governed reconciliation,
- and operations need near-real-time feeds. Lakehouse 2.0 assumes engine plurality and designs for it—rather than letting every workload fork its own pipeline and duplicate data.
3 . Multimodal governance becomes the hard problem (not storage) The estate will be increasingly multimodal: text, PDFs, call transcripts, images, embeddings, and graph relationships. The governance question shifts from “Where is the data?” to:
- What is it allowed to be used for (train/embed/answer)?
- Which engine accessed it?
- What lineage exists from source → feature/embedding → answer? Lakehouse 2.0 architectures win by making governance portable and consistent across modalities and engines.
A practical Microsoft example: Microsoft Fabric/OneLake is a strong illustration of the Lakehouse 2.0 direction:
- Delta is standardized across Fabric Lakehouse, aiming for consistent compatibility across Fabric workloads. (Microsoft Learn)
- OneLake supports Iceberg tables in a way that reduces friction: when you create or write to Iceberg folders, OneLake can generate virtual Delta metadata, and the reverse is supported too (Delta tables can expose virtual Iceberg metadata), improving interoperability across readers. (Microsoft Learn)
- OneLake shortcuts unify access across clouds and accounts without directly copying data, helping reduce duplication and “one more replica” sprawl. (Microsoft Learn)
- Open mirroring is positioned to replicate operational data into OneLake continuously while converting changes into Delta Parquet, reducing complex ETL for near-real-time integration. (Microsoft Learn)
Business impact: lower integration cost, less data duplication, faster onboarding of new engines and AI workloads, fewer governance blind spots, and better resilience when the ecosystem shifts (new model patterns, new engines, new compliance requirements). Without this, enterprises hit predictable pain: brittle pipelines, rising storage/egress costs, “which copy is correct?” disputes, and slow AI adoption because the context layer is fragmented.
CXO CTAs:
- Mandate open-format portability for new strategic domains: require Delta/Parquet/Iceberg alignment and test cross-engine readability as a release gate.
- Architect for multi-engine by design: define which engines are “approved” for which workloads—and enforce consistent governance across them.
- Reduce duplication as a policy, not a preference: treat new copies as exceptions requiring justification (risk, cost, audit impact).
- Extend governance to multimodal + vector/graph stores: classification, allowed-use rules, and lineage must apply beyond tables and dashboards.
- Build an interoperability roadmap: identify 2–3 high-friction domains and refactor them toward “one governed copy, many engines.”
Trend #5: Zero-Copy Integration & Data Virtualization Becomes Default — “Move Compute to Data” in the MCP Era
From 2026 through 2028, “copy the data into my platform” becomes the expensive default you have to justify, not the normal way of working. The reason is simple: AI and agents dramatically increase the number of consumers, tools, and workflows touching data. Every extra replica becomes a multiplier on security exposure, inconsistency, lineage breakage, and audit cost.
At the same time, the connectivity layer is changing. We’re entering an era of standardized agent connectivity—where agents connect to tools and data sources through consistent protocols, permissions, and observable connectors (think “MCP-era architecture”). That makes it possible to virtualize access and execution without materializing yet another copy.
The shift is from ETL/ELT-first thinking to selective materialization: virtualize by default, cache where it makes economic sense, materialize only where performance/regulatory constraints require it.
Three forces converge here:
- Data gravity and risk make “one more copy” a governance liability In AI programs, the data estate expands to include unstructured sources, embeddings, and derived artifacts. Copying everything to feed agents is not scalable—financially or operationally. Organizations will increasingly treat replication as a controlled exception and adopt patterns where compute comes to data (federation, virtualization, and governed shortcuts).
- Standardized Agent Connectivity changes integration economics (MCP-era architecture) As agents become a primary interface, enterprises need a consistent way to connect models to tools and systems safely. The Model Context Protocol (MCP) is explicitly framed as an open standard for building secure connections between data sources and AI tools. What matters operationally is not the acronym—it’s the consequences:
- tool permissioning becomes mandatory,
- connectors must be observable (what was called, by whom/what, and why), and
- tool use must follow least privilege with explicit consent and safety controls (MCP’s specification calls out tool safety and the need for explicit user consent before invoking tools).
3. Selective materialization becomes the new engineering discipline Virtualization isn’t magic—some workloads still need local materialization for performance, latency, or compliance. The difference is that materialization becomes designed and measured, not habitual. Expect routing decisions like:
- virtualize for exploration + wide access,
- cache for repeatable queries,
- materialize for certified “decision-grade” products with strict SLAs,
- and keep regulated domains in-place with controlled compute.
A practical Microsoft example: Microsoft Fabric’s OneLake shortcuts are a clear signal of the “zero-copy by default” direction: shortcuts are positioned as a way to connect to existing data without directly copying it, unifying access across domains and clouds through a unified namespace. Microsoft has also published guidance on OneLake security with shortcuts, including delegated shortcut patterns to share data securely without copying it—important when you’re trying to reduce shadow replicas without weakening governance. The practical leadership takeaway: zero-copy isn’t just a performance trick—it’s a governance strategy.
Business impact: lower integration cost, fewer “which copy is correct?” disputes, reduced security blast radius, faster onboarding of new AI consumers, and more defensible audit narratives (“we didn’t replicate sensitive data into five systems just to answer a question”). Without this shift, enterprises hit the same failure modes: data sprawl, inconsistent metrics, rising egress/storage costs, and governance teams permanently playing catch-up.
CXO CTAs:
- Make replication an exception: require justification for new copies (risk, audit, cost, and inconsistency impact) and set targets to reduce duplicate datasets.
- Adopt “virtualize by default” for AI access: stand up a governed access layer where agents and analysts can query where data lives, with caching and materialization only where needed.
- Treat connectors as security products: enforce least-privilege tool access, connector allowlists, and connector observability (who/what called which system, when, and with what result).
- Prepare for MCP-era standardization: define your enterprise stance on agent connectivity protocols, consent models, and tool safety—so “agent integration” doesn’t become a shadow IT free-for-all.
- Design selective materialization intentionally: identify the small set of domains that must be materialized for SLAs/compliance and industrialize them as certified decision-grade products.
Trend #6: AI-Native Data Engineering Automation (Augmented Data Management) — From Hand-Built Pipelines to “Assisted + Self-Healing” Operations
From 2026 through 2028, the limiting factor for data + AI scale won’t be ideas—it will be operational capacity. Teams simply can’t keep up with the volume of new sources, new products, new governance controls, and new agent use-cases using manual engineering alone. The result is a predictable squeeze: either reliability drops, or delivery slows to a crawl.
The winners will treat GenAI as an augmentation layer for the full data lifecycle—not just code generation. This includes automated transformations, test generation, documentation, lineage-aware triage, runbook automation, and increasingly, “self-healing” behaviors where pipelines detect issues, propose fixes, and route approvals.
The shift is from data engineering as build-and-maintain to data engineering as instrument-and-automate—where humans supervise and approve, and systems handle the repetitive work.
Three forces converge here:
- GenAI collapses the “time tax” of transformations, expressions, and boilerplate A huge portion of engineering time is spent on repetitive tasks: writing transformations, crafting pipeline expressions, mapping schemas, and fixing small-but-frequent issues. GenAI changes the default workflow to: describe intent → generate draft → validate with tests → ship. The productivity gain is real, but only durable when paired with shift-left checks and governance gates.
- Troubleshooting becomes assisted, and reliability becomes the product As estates grow, the hardest work becomes diagnosing failures: why did this pipeline break, why did the metric drift, what changed upstream, what’s the blast radius? This pushes toward automated error summarization, recommended remediations, and standardized incident playbooks—so the response is fast and consistent. Observability and data quality signals become the “sensors” that make this automation safe. Microsoft Purview’s data observability in Unified Catalog is explicitly positioned to provide an estate-level view of data health as data flows between sources—exactly the kind of backbone automation needs.
- Quality and documentation become continuously generated, not periodically written In an agentic world, documentation isn’t optional—it’s how you prevent teams (and agents) from misusing data. Expect automated generation and upkeep of: data descriptions, owner metadata, known limitations, and quality rules. Microsoft Purview Unified Catalog describes data quality as a way for owners to assess and oversee quality—directly tying trustworthy data to trustworthy AI outcomes. And Purview Data Quality supports configurable data quality rules (low/no-code) that can be used as repeatable checks rather than ad-hoc judgment calls.
A practical Microsoft example: Microsoft Fabric’s Data Factory is a clear illustration of where “augmented data management” is heading. Microsoft’s documentation states that Copilot in Fabric Data Factory can help create data integration solutions using natural language in both Dataflow Gen2 and pipelines, and can also troubleshoot pipelines with error summaries and recommendations. There’s also a Copilot experience for generating and explaining pipeline expressions—a common source of defects and rework. The leadership takeaway: use GenAI to remove toil—but keep humans in control through tests, approvals, and policy gates.
Business impact: faster delivery without lowering standards, fewer recurring incidents, reduced on-call burden, better documentation hygiene, and improved “data readiness” for AI use-cases. Without this trend, enterprises hit three failure modes: chronic pipeline fragility, rising operational load, and governance teams forced to become manual bottlenecks.
CXO CTAs:
- Make “automation coverage” a KPI: what % of pipelines have automated tests, quality checks, runbooks, and remediation playbooks? Track it like uptime.
- Shift-left quality and policy gates: require generated pipelines/transformations to pass contract checks, DQ rules, and policy validations before promotion.
- Standardize incident patterns for data: define “data incident” categories (freshness breach, reconciliation failure, lineage break, cost anomaly) and automate first-response steps.
- Adopt supervised self-healing: allow systems to propose fixes and create PRs/tickets automatically—but require approvals for changes that affect decision-grade outputs.
Invest in reliability roles and tooling: treat data reliability as an engineering discipline, not an afterthought (especially where agents consume outputs).
Trend #7: Decision Intelligence & Composite AI (Beyond GenAI) — From “Great Answers” to Better Decisions
From 2026 through 2028, enterprises will realize a hard truth: GenAI is excellent at language, not judgment. It can summarize, explain, draft options, and even recommend—but it does not reliably optimize trade-offs, forecast outcomes, or learn causality on its own. The organizations that win will move past “chat with data” into decision intelligence: GenAI combined with predictive models, causal inference, optimization, and scenario simulation—wrapped in feedback loops that learn from real outcomes.
This is the difference between AI as a productivity tool and AI as a management system.
The shift is from “answer generation” to decision systems that: predict what will happen, simulate alternatives, recommend actions, and measure whether those actions worked.
Three forces converge here:
- Decision quality becomes the KPI—not model quality Boards and CEOs won’t fund “more copilots” indefinitely. They’ll fund measurable improvements like faster closes, fewer churned customers, fewer stockouts, lower fraud, and improved margins. That pushes teams to instrument decision outcomes, not just response accuracy. It also forces “cost-per-outcome” thinking: model calls + tool calls + human review + rework.
- Composite AI becomes the operating pattern GenAI explains and orchestrates. Predictive models forecast. Optimization allocates resources. Causal methods reduce “false confidence” by distinguishing correlation from drivers. Together, they enable:
- scenario planning (“if we change pricing by X, what happens?”),
- decision simulation (“what’s the best action given constraints?”), and
- decision feedback loops (“did the action improve the metric, and why?”). In practice, enterprises will build “decision stacks” per domain (supply chain, finance, CX, risk) rather than one monolithic AI approach.
3. Closed-loop learning becomes the differentiator Most AI programs stall because they don’t learn from outcomes. Decision intelligence requires a loop: action → result → attribution → policy/model update. That drives governance requirements too: you need to know what the system recommended, what was approved, what was executed, and what the outcome was—so you can improve safely.
A practical Microsoft example: This is where the Microsoft ecosystem can be assembled into a decision loop (again: the advantage is operational coherence, not magic).
- Predictive layer: Azure Machine Learning’s AutoML explicitly supports time-series forecasting workflows (setup, train, evaluate), which is foundational for decisioning in demand, staffing, revenue, and risk.
- Analytics-to-predictive bridge: Microsoft Fabric positions Data Science as enabling teams to build and operationalize ML models, and specifically notes integrating predictions into BI so organizations shift from descriptive to predictive insights.
- Scenario layer: Power BI supports “What-if” parameters to vary assumptions and see the effect on measures—useful for lightweight scenario analysis embedded in business workflows.
- Real-time decision triggers: Fabric Real-Time Intelligence is positioned for analyzing data in motion and taking actions on events—critical when decisions need to respond to live signals (fraud spikes, outage storms, inventory shocks).
Business impact: better forecasting and planning accuracy, faster and more consistent decisions, fewer “reaction cycles,” and tangible margin improvements because decisions are optimized under constraints instead of debated endlessly. Without decision intelligence, GenAI often produces a polished narrative around weak underlying logic—leading to “fast wrong decisions” or “slow human overrides” that erase productivity gains.
CXO CTAs:
- Pick 5 decision loops to industrialize (not 50 copilots): define the decision, the outcome metric, the constraints, and the allowable actions—then build a composite AI approach per loop.
- Instrument outcome-level measurement: track prediction error, decision latency, approval rates, reversals, and realized value (not just usage or satisfaction).
- Adopt scenario simulation as a standard artifact: require “options + modeled impacts + confidence bands” for material decisions, not narrative-only recommendations.
- Build closed-loop learning with governance: capture action logs, approvals, and outcomes so models/policies can improve safely over time.
- Separate “explain” from “decide”: use GenAI to explain and orchestrate, but anchor decisions in predictive/optimization logic with explicit guardrails.
Trend #8: Unified Trust Plane for Data + AI (Programmable Trust) — Governance Moves From “Policy PDFs” to Runtime Control
From 2026 through 2028, enterprise trust will be won by teams who can enforce policy—not just document it. As copilots and agents start answering and acting, governance must execute at runtime: what data can be accessed, what can be embedded, what can be answered, and what tools can be invoked—under auditable controls.
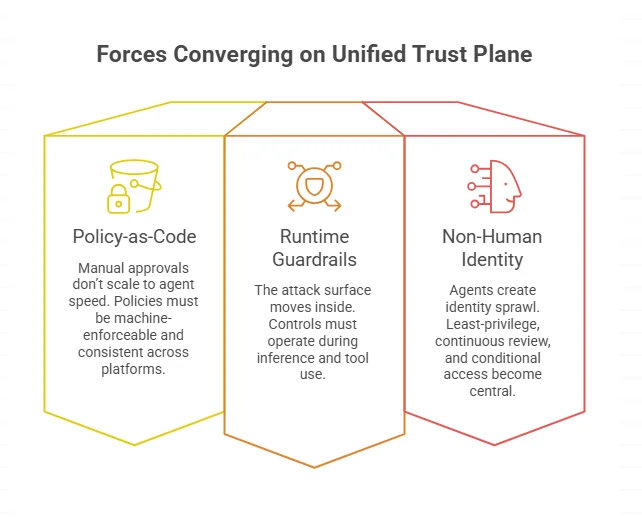
The shift is from governance as review to governance as programmable enforcement across data + AI + tools.
Three forces converge here:
- Policy-as-code becomes the only scalable model Manual approvals don’t scale to agent speed. Policies must be machine-enforceable (classification, access, DLP, allowed-use) and consistent across platforms and modalities.
- Runtime guardrails replace perimeter thinking The attack surface moves inside: prompt injection, data exfil via tool calls, and unsafe actions. Controls must operate during inference and tool use—not only at storage time.
- Non-human identity + tool permissions become the new “privileged access” problem Agents create identity sprawl. Least-privilege, continuous review, and conditional access for workload identities becomes central to keeping tool access safe.
A practical Microsoft example:
- Purview data policy enforcement enables enforcing data policies on registered resources (runtime control vs. “advice”).
- Purview DLP for Fabric can detect sensitive data uploads into Power BI semantic models (with alerts and optional overrides), bringing compliance control into analytics flows.
- Microsoft Entra Workload ID is positioned to secure workload identities with conditional access and least-privilege discipline—critical for agent/tool identities.
- Azure Prompt Shields helps detect/block adversarial prompt attacks before generation—useful as a guardrail against tool abuse and data exfil attempts.
Business impact: faster AI rollout with fewer policy exceptions, reduced leakage risk, fewer “agent incidents,” and audit-ready evidence of what was accessed and why. Without a unified trust plane, you’ll see the same failure modes: shadow access, inconsistent enforcement, and reactive governance that arrives after damage.
CXO CTAs:
- Mandate runtime-enforceable policies: if a control can’t block/allow in-system, it doesn’t count.
- Treat tool-use like privileged access: allowlists, least-privilege permissions, and full tool-call audit trails.
- Secure non-human identities: inventory, conditional access, periodic reviews, and anomaly detection for workload identities.
- Adopt inference guardrails: prompt injection defenses + safe tool invocation patterns as part of the standard AI release checklist.
Trend #9: Adaptive Governance (Continuous Classification + Risk-Scored Controls) — From Static Controls to “Policy That Moves With the Data”
From 2026 through 2028, governance will stop being a quarterly exercise and become a continuous system. Why? Because data is no longer just stored and queried—it’s embedded, summarized, answered from, and acted on by agents. Static access lists and manual reviews can’t keep up. Enterprises will move to continuous classification and risk-scored controls that adapt based on sensitivity, purpose, user context, and intended AI use.
The shift is from “one-time classification + static RBAC” to dynamic controls: purpose-based access, dynamic masking, and explicit AI permissions like allowed-to-train and allowed-to-answer.
Three forces converge here:
- Classification must be continuous (and automated) Data changes, moves, and gets re-packaged (lakehouse items, semantic models, documents, embeddings). Governance has to keep labeling up-to-date—automatically—otherwise controls drift behind reality. Microsoft supports automatically applying sensitivity labels to Microsoft 365 items when conditions match.
- Controls become risk-scored and purpose-based “Can access” isn’t binary anymore. You need policy that asks: Why are you accessing it? What are you trying to do (view/export/embed/train/answer)? That drives dynamic masking, conditional access, and exception workflows tied to risk.
- AI usage creates new policy verbs: allowed-to-train / allowed-to-answer Enterprises will formalize AI-specific permissions and enforcement paths so sensitive data doesn’t quietly leak into prompts, embeddings, or generated answers. Microsoft Purview positions capabilities to mitigate and manage risks associated with AI usage, including governance/protection controls.
A practical Microsoft example:
- DLP in Fabric/Power BI can detect sensitive info as it’s uploaded into semantic models, generate policy tips/alerts, and support overrides—useful as adaptive control at ingestion/usage time.
- Protection policies (preview) are designed to automatically protect sensitive data using sensitivity labels and restrict access based on detected sensitivity—closer to “risk-scored control” than static permissioning.
Business impact: fewer policy gaps, faster enablement (because controls adapt instead of blocking everything), lower leakage risk into AI, and cleaner audit posture because enforcement is consistent and logged. Without adaptive governance, you’ll see predictable failure modes: over-restriction (users bypass), under-restriction (leakage), and endless exception handling.
CXO CTAs:
- Mandate continuous classification: automate labeling for high-risk domains and make “unlabeled” a policy exception, not normal.
- Define AI-specific allowed-use policies: allowed-to-train / allowed-to-embed / allowed-to-answer / allowed-to-export—then enforce them in platforms and workflows.
- Adopt risk-scored controls: dynamic masking, conditional access, and purpose-based policies for sensitive categories.
- Instrument governance like operations: track exceptions, overrides, and policy hits as leading indicators of both risk and friction.
Trend #10: Applied Observability & Data Reliability Engineering — Treat Data Like a Production Service
From 2026 through 2028, data failures will increasingly be treated like outages—because they cause outages in decisions: wrong pricing, delayed close, broken claims workflows, and agents taking actions on stale or inconsistent context. The organizations that scale AI safely will operationalize Data Reliability Engineering (DRE): measurable SLOs, incident playbooks, lineage-aware blast radius, and cost/entropy monitoring.

The shift is from “monitor pipelines” to observability across the full chain: pipeline → serving layer → consumption (BI/AI) → business outcomes.
Three forces converge here:
- Consumption observability becomes as important as pipeline observability It’s not enough to know a job succeeded—you need to know whether the right data was consumed (freshness, reconciliation, definition stability) and who/what depended on it (dashboards, copilots, agents).
- Lineage-aware incident response becomes mandatory When something breaks, the first question becomes: what’s the blast radius? Lineage needs to drive containment, stakeholder alerts, and rollback/degraded modes—fast.
- Cost anomalies and data entropy become leading indicators of failure Runaway spend, duplication, and “random walk” metric drift are early warning signals. Reliability teams will treat cost spikes, unexpected materializations, and access pattern shifts as governance + operational events, not just FinOps noise.
A practical Microsoft example:
- Microsoft Purview Unified Catalog includes Data observability (preview) to provide a “bird’s eye view” of data estate health and lineage-aware views—useful for reliability management at scale.
- Microsoft Fabric provides a Monitor hub to centrally monitor Fabric activities (what ran, what failed, what’s active) across artifacts you have permissions to view.
- Fabric user activities are logged and available in Microsoft Purview Audit, improving traceability when diagnosing “who changed what / who accessed what.”
Business impact: fewer decision incidents, faster containment, lower rework, reduced on-call fatigue, and higher confidence in agent-driven workflows because data health is measurable and actionable.
CXO CTAs:
- Define DRE SLOs for decision-grade domains: freshness, reconciliation, semantic stability, and access integrity—then operationalize alerts + escalation.
- Run data incidents like reliability incidents: standard severity levels, time-to-contain targets, and post-incident fixes that prevent recurrence.
- Make lineage operational: blast-radius mapping, automated stakeholder notification, and controlled degraded modes when SLOs breach.
- Instrument cost + duplication as reliability signals: treat unexpected materialization and spend spikes as triggers for investigation and governance review.
Trend #11: Data Security Evolves to DSPM + Exposure Management — Finding Shadow Data, Securing AI Stores, and Adding DisInfoSec
From 2026 through 2028, “data security” stops being a set of point controls and becomes a continuous posture + exposure discipline. The hard part isn’t protecting what you know—it’s finding what you don’t: shadow data, shadow access, risky flows, and sensitive content spreading into unstructured stores, vector indexes, and AI apps.
The shift is from protecting known systems to continuously discovering, prioritizing, and remediating exposure—across traditional apps and AI copilots/agents.
Three forces converge here:
- Shadow data becomes the dominant risk surface AI adoption increases copying, summarization, and embedding—creating sensitive “data exhaust” in places teams don’t govern well (docs, chats, exports, ad-hoc storage, vectors). If you can’t discover and classify continuously, you can’t secure the estate.
- DSPM becomes the control tower (including for AI apps and agents) DSPM is emerging as the unifying layer to monitor posture, identify unprotected sensitive data, and drive remediation across the estate. Microsoft Purview DSPM is explicitly positioned to help discover, protect, and investigate sensitive data risks and provide unified visibility/control for both traditional applications and AI apps/agents. And Microsoft’s DSPM for AI frames the requirement directly: a central place to secure data for AI apps and proactively monitor AI use (Copilots, agents, and other genAI apps).
- DisInfoSec becomes a data governance responsibility, not just comms Deepfakes, impersonation, and manipulated content will trigger real enterprise incidents: fraud, brand damage, and operational disruption. Defending against disinformation requires verified provenance, content authenticity signals, and integrity incident response—not just “security awareness training.” Microsoft has publicly highlighted efforts to fight deepfakes and improve transparency about AI-generated content, reflecting how mainstream this becomes.
A practical Microsoft example:
- Microsoft Purview DSPM provides posture reporting and risk visibility for sensitive data exposure across environments.
- Microsoft Purview Data Security Investigations uses generative AI to help analyze and respond to data security incidents and sensitive data exposure—useful when “find impacted data fast” becomes the priority.
- Pairing DSPM + investigations creates a pragmatic loop: discover exposure → prioritize → investigate → remediate.
Business impact: reduced leakage risk (especially into AI contexts), faster time-to-contain data incidents, clearer accountability for sensitive data sprawl, and fewer surprises during audits and breaches. Without DSPM-style exposure management, enterprises repeat the same failure modes: unknown sensitive data, unmanaged access paths, slow investigations, and repeated incidents.
CXO CTAs:
- Make “find shadow data” a quarterly objective with metrics: % of sensitive data discovered/classified, top exposure hotspots, time-to-remediate.
- Extend posture management to AI stores: unstructured + vector/graph repositories, embeddings pipelines, and AI app connectors must be in-scope for classification and controls.
- Operationalize exposure remediation: automate the top 10 fixes (labeling gaps, overly broad sharing, risky links, unprotected repositories).
- Stand up DisInfoSec playbooks: verified provenance for critical content, deepfake/impersonation response, and executive escalation paths.
Trend #12: Privacy-Preserving Collaboration + Confidential Compute — Share Value, Not Raw Data
From 2026 through 2028, data collaboration will expand (partners, regulators, joint AI), but “send me a copy” won’t survive privacy, sovereignty, or competitive risk. Enterprises will adopt clean rooms + PET patterns + confidential computing to collaborate while keeping data private in-use, not just at-rest/in-transit.
The shift is from sharing datasets to sharing governed computation—with provable controls over what each party can learn.
Three forces converge here:
- Clean rooms become the default for partner analytics and joint AI Secure multiparty collaboration will move into clean room patterns where parties combine data for analytics/ML without exposing raw inputs. Azure Confidential Clean Rooms is explicitly designed for multiparty collaboration while preventing outside access to data.
- Confidential compute operationalizes “data-in-use” protection Confidential computing protects data while it’s being processed using hardware-based, attested Trusted Execution Environments (TEEs). This matters because it turns privacy from a contractual promise into an enforceable runtime property.
- Queryable encryption patterns become viable in select workloads Techniques like enclave-based confidential queries reduce exposure when you must compute over sensitive fields. Microsoft’s “Always Encrypted with secure enclaves” expands confidential query capability while keeping sensitive data protected.
A practical Microsoft example:
- Azure Confidential Clean Rooms for regulated partner collaboration and joint analytics/ML.
- Azure Confidential Computing for TEE-backed data-in-use protection (including confidential VMs).
- Enclave-backed confidential queries via Always Encrypted with secure enclaves for scenarios where sensitive fields must remain protected during computation.
Business impact: faster partner value creation without data handoffs, reduced legal/compliance friction, safer AI fine-tuning/inferencing across parties, and fewer “data-sharing kills the deal” outcomes.
CXO CTAs:
- Identify 3 collaboration use-cases (marketing measurement, fraud, healthcare outcomes, supply chain) and redesign them as clean-room-first.
- Make “data-in-use” a requirement for regulated cross-party analytics and AI.
- Standardize PET decisioning: when to use clean rooms vs confidential compute vs encryption patterns—by workload type and risk.
- Contract for outputs, not copies: define allowed outputs, disclosure limits, retention, and audit evidence up front.
Trend #14: Federated Architecture & Governance Operating Model (Mesh vs Fabric vs Hybrid) — Central Policy, Distributed Execution
From 2026 through 2028, the hardest part of data + AI won’t be picking a platform—it will be running the operating model. As domains ship data products and agents consume them, governance has to scale without becoming a bottleneck. Most enterprises will converge on a hybrid: centralized standards and assurance, with distributed ownership and enforcement embedded in platforms and teams.

The shift is from centralized control to a hub-and-spoke trust model: a central hub defines policy, identity, audit, glossary/ontology standards—while domains execute, monitor, and improve with clear accountability.
Three forces converge here:
- AI forces decisions closer to domains Agents need domain context, semantics, and fast iteration. Central teams can’t be the single queue for every change without killing speed.
- Standards must be centralized to preserve trust Even in a federated model, you need one “truth layer” for policy categories (allowed-to-train/answer/export), identity patterns, audit expectations, and semantic definitions. Otherwise you get 30 different governance interpretations—and zero defensibility.
- Funding and accountability have to change Data products require product management, SLAs, and lifecycle ownership. Without a clear funding model (shared services + domain budgets), mesh becomes “everyone does whatever,” and fabric becomes “central team can’t keep up.”
A practical Microsoft example: In Microsoft-heavy enterprises, this often lands as a hybrid where a central team sets Purview-led standards for classification, policy, and audit expectations, while domain teams build and operate governed data products in Fabric; the point isn’t the tools, it’s that the organization can keep one governance spine (identity, policy language, audit posture, glossary) while letting domains move fast inside an approved envelope—so copilots/agents can scale without turning governance into a helpdesk.
Business impact: faster delivery with consistent trust, clearer ownership for data products, fewer semantic conflicts, and better audit posture because standards are uniform even when execution is distributed. Without the operating model, you get either central bottlenecks (slow) or domain chaos (untrusted).
CXO CTAs:
- Choose a deliberate hybrid: define what is centralized (policy, identity, audit, semantics standards) vs. what is federated (domain products, SLAs, pipelines, local controls).
- Stand up a Governance Hub with teeth: a small central team that ships standards-as-code, not slide decks.
- Fund data products like products: ownership, SLAs, lifecycle, and capacity—make it measurable.
- Embed governance in platforms and pipelines: enforcement should happen where work happens (CI/CD, access flows, tool-use), not via email approvals.
Trend #15: Data Products as the Business Scaling Unit and Revenue Engine — From “Datasets” to Managed, Monetizable Capabilities
From 2026 through 2028, the organizations that scale AI and analytics won’t scale by building more pipelines—they’ll scale by shipping data products: reusable, documented, SLA-backed assets (with semantics, access patterns, and quality guarantees) that plug directly into workflows and agents. In many industries, the next step is unavoidable: some of these products become external-facing—partner APIs, packaged insights, and decision services that create new revenue streams.
The shift is from data as an internal byproduct to data as a business capability with owners, unit economics, and measurable adoption.
Three forces converge here:
- Agents need stable “interfaces,” not raw tables Copilots and automated workflows can’t negotiate meaning every time. Data products provide the contract: definitions, freshness, quality signals, and allowed-use—so outcomes are repeatable.
- Activation moves into operations, not dashboards The value isn’t “insight.” It’s “insight that triggers the right action.” Data products that integrate with CRM, finance, supply chain, and service workflows become the scaling lever.
- Unit economics becomes visible (and accountable) As AI usage grows, leaders will ask: cost-to-produce, cost-to-serve, adoption, business impact, and whether the product should be simplified, retired, or monetized.
A practical Microsoft example: In Microsoft-centric enterprises, data products often land as a curated layer built on Fabric (with consistent semantic definitions), governed through Purview, and exposed through approved APIs/workflows into Power Platform and Microsoft 365 surfaces—so a “Customer Health” or “Fraud Risk” product can be reused across reporting, copilots, and operational automation with clear ownership, SLAs, and access controls.
Business impact: faster reuse, fewer duplicate builds across teams, higher trust in AI-assisted actions, and a clean path to partner monetization (packaged insights and decision services) without leaking raw data.
CXO CTAs:
- Name your first 10 data products: pick domains tied to real decisions (pricing, churn, risk, inventory) and assign product owners.
- Require SLAs + semantics + allowed-use: no “product” without freshness, quality signals, definitions, and AI permissions.
- Measure adoption and value per product: usage, cycle-time reduction, avoided loss, margin lift—tie funding to outcomes.
- Design for activation: ship the product into workflows (tickets, approvals, outreach, replenishment), not just dashboards.
Trend #16: Semantic + Metadata Authority Operating System — One Definition the Business Can Defend
From 2026 through 2028, most “AI accuracy” failures in enterprises will trace back to something painfully non-AI: semantic disagreement. What exactly is “active customer”? How is “gross margin” calculated? Which dimension is conformed across regions? Agents will amplify this problem because they answer quickly and at scale—so ambiguity becomes a trust incident, not a debate in a meeting.
The shift is from metadata as documentation to metadata + semantics as an authority system: versioned, governed, testable, and enforced wherever data is consumed (BI, APIs, and AI retrieval).

Three forces converge here:
- Metrics become enterprise APIs (and must be governed like APIs) As teams operationalize decisions, metrics stop being “report logic” and become shared products. That requires ownership, change control, and compatibility promises—or every team gets a different truth.
- Metadata needs an authority layer, not just accumulation Catalogs are not enough if they don’t resolve conflicts. The winning pattern is “metadata about metadata”: confidence, source-of-truth, ownership, and drift detection—so consumers know what to trust.
- Dimensional modeling returns—modernized (“Star Schema 2.0”) The future isn’t abandoning modeling; it’s making it contract-driven: metric-first semantics, conformed dimensions via contracts, and governance that blocks breaking changes before they land in decision flows.
A practical Microsoft example : In Microsoft-heavy environments, this authority layer often emerges by combining a governed semantic model approach in Power BI/Fabric with centralized glossary/metadata stewardship in Purview, so common measures and dimensions are published once, versioned, and reused consistently across reports, copilots, and data agents—reducing the “multiple truths” problem that otherwise shows up as inconsistent AI answers.
Business impact: fewer metric disputes, faster decision cycles, higher AI answer consistency, and simpler governance because definitions are enforced centrally while used everywhere. Without a semantic authority system, enterprises get “analysis paralysis” at best and automated wrong actions at worst.
CXO CTAs:
- Declare a small set of enterprise metrics as “authoritative”: assign owners, definitions, and change control.
- Adopt metric-first semantics + conformed dimensions: standardize what must be shared, and contract-test it.
- Make semantic drift measurable: monitor definition changes, conflicting logic, and downstream breakage risk.
- Enforce reuse: reward teams for consuming certified semantics instead of rebuilding them locally.
Trend #17: Hybrid Context Plane (Graph + Vector + Search + Knowledge) — Governed Context Assembly Becomes the Real Differentiator
From 2026 through 2028, competitive advantage will shift from “having data” to assembling the right context for every question and action. Pure vector search won’t be enough: enterprises will adopt a hybrid context plane that blends keyword + vector retrieval, knowledge graphs, and curated semantic layers—because agents need precision, coverage, and policy constraints, not just similarity.
The shift is from “RAG as a feature” to context engineering as a platform capability: governed retrieval policies, multimodal indexing, GraphRAG patterns for deeper reasoning, and repeatable context recipes per domain.
Three forces converge here:
- Hybrid retrieval becomes the default pattern Enterprises will combine vector similarity with lexical precision in a single query, then fuse results—because it reduces both missed facts and irrelevant matches (especially for regulated language and exact terms). Azure AI Search documents this hybrid approach (vector + full-text in one request, merged via ranking fusion).
- GraphRAG emerges for “why/what’s connected” questions When users ask for narratives, drivers, and relationships across documents, graph-based retrieval patterns outperform snippet search by structuring entities and connections first. Microsoft Research’s GraphRAG describes combining text extraction, network analysis, and LLM summarization into an end-to-end system for understanding private corpora.
- Retrieval policy constraints become mandatory The context plane must obey allowed-use rules (allowed-to-answer/allowed-to-embed), row-level security, and purpose limitations—otherwise your agent will “retrieve the right thing” in the worst possible way.
A practical Microsoft example: Microsoft is converging multiple building blocks into this context plane: Azure AI Search supports vector and hybrid retrieval for RAG scenarios , it includes an indexer specifically for OneLake files so curated lakehouse content can be indexed with metadata , and Fabric’s “data agents” are designed to enable conversational Q&A over governed data in OneLake —together signaling that “governed context assembly” (not just a model) is the enterprise pattern.
Business impact: more consistent and defensible answers, fewer hallucination-driven escalations, faster domain agent rollout, and better containment because you can constrain what context is eligible for retrieval.
CXO CTAs:
- Treat context as an asset: define approved context sources per domain (tables, docs, policies, graphs) and manage them like products.
- Standardize retrieval patterns: hybrid search as default; GraphRAG where relationship reasoning matters.
- Enforce retrieval policy constraints: “what can be retrieved” must be governed the same way as “what can be accessed.”
- Measure answer quality operationally: hit rate, citation coverage, stale-context incidents, and time-to-contain retrieval failures.
Trend #18: Data Lifecycle Management & Data Minimization — Right-to-Delete Extends to Embeddings and AI Outputs
From 2026 through 2028, enterprises will learn that “keep everything” is no longer just expensive—it’s risky. AI makes retention visible because it turns old, sensitive, or incorrect data into fresh answers. Lifecycle management will expand beyond tables to include embeddings, vector indexes, prompts, and GenAI outputs, with enforceable retention, deprecation, and right-to-delete that actually works end-to-end.
The shift is from storage-centric retention to policy-driven lifecycle enforcement across raw data + derived data + AI artifacts.

Three forces converge here:
- Regulatory pressure meets AI amplification Retention and deletion obligations become harder when data is copied into features, embeddings, and generated artifacts. If you can’t prove deletion propagation, you don’t have deletion—just intention.
- Vector lifecycle management becomes a real operational requirement (“vector rot”) Embeddings decay as language, products, and policies change. Without refresh and deprecation rules, your retrieval layer becomes stale and misleading—quietly.
- Minimization becomes a performance and trust advantage Smaller, curated, policy-compliant context reduces cost and improves answer quality. Minimization is not only compliance; it’s how you keep agents precise.
A practical Microsoft example : In Microsoft environments, lifecycle enforcement typically threads through Microsoft Purview’s retention and disposition capabilities for Microsoft 365 content and related records management controls , while teams operationalize AI artifact lifecycle (indexes, embeddings, generated summaries) alongside Fabric/OneLake governance so “what we keep” and “what AI can answer from” stays aligned as content ages, policies change, or deletion requests arrive.
Business impact: reduced legal exposure, lower storage and retrieval cost, fewer stale-answer incidents, and stronger defensibility because “what the agent used” remains current and policy-compliant.
CXO CTAs:
- Extend retention policy to AI artifacts: embeddings, indexes, prompts, and generated outputs must have owners and lifecycle rules.
- Implement deletion propagation: prove right-to-delete across derived stores (features/vectors/outputs), not just source systems.
- Operationalize vector refresh: define refresh triggers (policy change, product change, drift signals) and retirement rules.
- Adopt minimization for AI context: curate eligible sources; reduce over-retrieval as a quality + cost control.
Trend #19: Closed-Loop DataOps + ValueOps — Prove Value, Stop Leakage, and Run AI/Analytics Like a Portfolio
From 2026 through 2028, the problem won’t be building more data and AI—it will be proving they pay back and preventing value leakage through rework, duplicated products, runaway capacity spend, and “insight that never becomes action.” Leaders will institutionalize ValueOps: benefits tracking, unit economics, portfolio governance, and energy-aware FinOps—so every major data/AI initiative has a measurable outcome and a controlled cost curve.
The shift is from “delivery metrics” (pipelines shipped, dashboards built) to outcome economics: cost-per-decision, time-to-decision, and realized impact per data product/agent.
Three forces converge here:
- AI makes variable cost unavoidable As agents and copilots scale, spend becomes operational: inference, storage, movement, and capacity. Without unit economics, productivity programs can cost more than they save.
- Value leakage is mostly operational, not strategic Most loss comes from stale metrics, broken pipelines, duplicated datasets, manual verification, and “shadow rebuilds.” Closed-loop ops finds and fixes leakage continuously.
- Energy-aware FinOps becomes part of governance As compute grows, efficiency and sustainability pressures converge; enterprises will increasingly treat carbon/energy signals as optimization inputs alongside cost and performance. Microsoft explicitly links FinOps practices with sustainability optimization (e.g., Azure Carbon Optimization and emissions insights).
A practical Microsoft example: Microsoft-heavy teams can operationalize ValueOps by correlating platform consumption to business outcomes using Fabric capacity telemetry: the Microsoft Fabric Capacity Metrics app is built to monitor capacity consumption and inform scaling/autoscale decisions , and Microsoft documents how to correlate your Azure bill with Fabric usage analytics (billable usage by item/workload in CUs) —which is exactly what you need to move from “we shipped it” to “here’s the cost-per-outcome and where to optimize.”
Business impact: predictable unit economics, fewer duplicate builds, faster decision cycles, tighter reliability, and a portfolio that compounds value instead of accumulating “analytics debt.”
CXO CTAs:
- Define cost-per-outcome for top workflows: include platform consumption + tooling + human review + rework.
- Stand up a quarterly ValueOps review: stop/start/scale decisions for data products and agents based on measured impact and unit economics.
- Instrument value leakage: track rework, manual verification time, repeated incidents, and duplicated products as leading indicators.
Bake FinOps into platform governance: capacity planning, autoscale rules, workload placement, and sustainability signals as standard controls.
Trend #20: AI-Ready Data Engineering — Readiness Scoring, Correctness SLOs, and Context Engineering Become Standard
From 2026 through 2028, “data engineering” stops being mainly about moving and shaping data—and becomes about proving fitness for AI-driven decisions. When copilots and agents are answering questions and triggering workflows, the tolerances change: freshness drift, metric ambiguity, and silent pipeline breakage become business incidents, not technical defects.
The organizations that scale AI safely will treat data like an operational product: readiness-scored, SLO-backed, policy-gated, and transparent at the point of use. Everyone else will ship agents that look smart in demos but fail under real-world ambiguity.
The shift is from “pipeline delivery” to data reliability + context delivery—with measurable correctness and enforceable controls.
Three forces converge here:
- Readiness scoring becomes a prerequisite for agent scale Before you let agents use a dataset (or a semantic model), you’ll need an objective answer to: Is this data fit for automated decisions? That drives readiness scoring across: quality, freshness, completeness, lineage confidence, ownership, and policy status. In practice, this becomes the new release checklist—like security reviews became mandatory over the last decade.
- Correctness SLOs replace vague quality promises “Data quality” becomes measurable in the way SRE made uptime measurable. Expect correctness SLOs such as:
- freshness (max staleness),
- completeness/coverage,
- reconciliation (source vs serving consistency),
- definition stability (metric drift),
- and “known-bad data” blast-radius containment. SLO breaches won’t be vanity dashboards—they’ll trigger alerts, incident response, and automated rollback/degraded-mode behaviors.
3. Context engineering becomes as important as transformation engineering In the agentic era, the question isn’t only “Is the table correct?” It’s “Is the context assembled for the answer correct and policy-compliant?” That drives: retrieval constraints, governed joins, approved semantic definitions, and data transparency labels presented with every answer (freshness / coverage / confidence / owner). If users can’t see these signals, they will trust the wrong thing—fast.
A practical Microsoft example: Microsoft is explicitly building primitives that support this “AI-ready” posture. In Microsoft Purview Unified Catalog, data quality is treated as an oversight capability where teams can assess and manage quality, including data quality rules and data quality scans that produce scores. (Microsoft Learn) Purview Unified Catalog also introduces data observability (preview) to view estate health and lineage-aware views—important when you’re trying to operationalize correctness, not just document it. (Microsoft Learn) On the engineering side, Microsoft Fabric’s Data Factory includes Copilot capabilities positioned to help design data flows and even generate/summarize pipelines—useful for accelerating delivery, but only safe when paired with shift-left tests, policy gates, and SLO enforcement. (Microsoft Learn)
Business impact: higher AI answer accuracy, fewer “confidence incidents,” faster time-to-production for agents (because readiness is clear), and reduced operational drag from firefighting data issues. Without AI-ready engineering, you’ll see the same three failure modes repeat: agents using stale data, metric disputes that stall decisions, and repeated manual verification that erases productivity gains.
CXO CTAs:
- Define “AI-ready” as a measurable standard: publish a readiness scorecard (quality, freshness, lineage, ownership, policy status) and require it before any dataset is used by copilots/agents.
- Adopt correctness SLOs for top decision flows: set SLOs (freshness, completeness, reconciliation, semantic stability) and wire them to alerts + incident playbooks.
- Implement policy gates in delivery pipelines: no promotion to “decision-grade” without passing automated checks and policy validations.
- Make transparency visible at the point of answer: every AI response should show freshness/coverage/confidence/owner—so trust becomes informed, not implicit.
- Invest in context engineering as a discipline: govern retrieval + semantics + joining rules so “what the agent saw” is controlled and explainable.
Trend #21: Sovereignty + Continuous Compliance + Audit-Grade Measurement (incl. PQC Planning) — Compliance Becomes “Always-On”
From 2026 through 2028, data and AI will be governed as sovereign flows, not static assets. Enterprises will need to prove—continuously—where data moved, which policies applied, and what controls were enforced, with evidence that stands up to auditors. At the same time, forward-looking organizations will start practical post-quantum readiness planning so today’s encryption decisions don’t become tomorrow’s exposure.
The shift is from periodic compliance reporting to evidence-as-code: continuously measured controls, tamper-evident logs, and controlled override mechanisms.
Three forces converge here:
- Sovereignty constraints become architectural Residency, cross-border rules, sector regulations, and customer contractual terms will dictate where data can be processed—including where AI inference can occur and where context can be retrieved from.
- Audit expects proof, not intent “Policy exists” won’t pass. You’ll need audit-grade evidence: what ran, what was accessed, what was masked, what was exported, and who approved exceptions.
- PQC planning shifts from theory to roadmap You don’t need to “flip everything” overnight, but you do need inventory, prioritization, and a transition plan—especially for long-lived sensitive data and identity/keys.
A practical Microsoft example : In Microsoft-centric estates, this typically translates into using Azure’s policy and identity controls to constrain where workloads run, Microsoft Purview to standardize classification and auditing expectations across data/analytics surfaces, and an explicit cryptography/keys roadmap (with managed key management patterns) so teams can show auditors a continuous evidence trail today while building a realistic PQC transition plan over the next 24–36 months.
Business impact: faster approvals for regulated AI use-cases, fewer audit scrambles, reduced cross-border risk, and fewer “compliance surprises” that stall deployment late in the program.
CXO CTAs:
- Map sovereignty zones: define where data/AI can run by domain (residency, access, inference, context retrieval).
- Operationalize evidence-as-code: automate control checks and produce audit-ready logs as a byproduct of execution.
- Design controlled overrides: exceptions should be time-bound, approved, and logged—never informal.
- Start PQC readiness now: inventory cryptography dependencies, classify “harvest-now, decrypt-later” risk areas, and build a phased migration plan.
Trend #22: New Durable Data / Analytics / AI Roles — Agent Supervisors, Ontology Engineers, and Reliability as a Career Path
From 2026 through 2028, the biggest capability gap won’t be “how to use GenAI.” It will be who runs the new system of work: data products with SLAs, governed context planes, agent workflows, and programmable trust. Job titles will stabilize around durable responsibilities—because you can’t scale this through heroics or a central COE alone.
The shift is from generalist teams doing “a bit of everything” to clear role specialization that matches the new operating model.
Three forces converge here:
- Data products require product management, not just engineering If you want reuse and accountability, you need Data Product Owners who own adoption, SLAs, semantic clarity, and lifecycle—not just delivery.
- Context and semantics become first-class engineering disciplines As retrieval and semantics drive AI outcomes, enterprises will formalize roles like ontology/context engineers who manage meaning, relationships, and governed context assembly.
- Reliability and supervision become permanent needs Agentic systems require people who design controls, monitor behavior, and manage incidents. Data Reliability Engineers and Agent Supervisors will become as normal as SREs in software—because the cost of silent failure is too high.
A practical Microsoft example : In Microsoft-heavy organizations, these roles often align naturally with how the platform is used: Fabric-focused teams operate data products and semantic layers, Purview-aligned roles steward classification and policy enforcement, and security/identity teams extend Entra patterns to non-human identities and agent tool access—making “trust operations” a shared, durable responsibility rather than a one-off project.
Business impact: faster scale with fewer incidents, clearer accountability, reduced bottlenecks, and a talent model that keeps governance and reliability from becoming the brakes on AI.
CXO CTAs:
- Define your target org design: which roles sit centrally (policy, identity, audit) vs. in domains (product, reliability, context).
- Create career paths for reliability and governance engineering: make it prestigious, not “support work.”
- Assign named owners to decision-grade products: no owner, no SLA, no production.
- Stand up agent supervision as a function: monitoring, controls, escalation, and continuous improvement for agent workflows.
Trend #23: Data Literacy as a Strategic Capability — Literacy for the Agentic Era (Not Just “Dashboard Training”)
From 2026 through 2028, data literacy will determine whether AI becomes a competitive advantage or a compliance and trust problem. As copilots and agents turn data into answers and actions, every role needs the ability to interpret confidence, challenge definitions, and spot risky automation. Gartner’s 2024 CDAO survey signals this gap clearly, citing poor data literacy among the top roadblocks to D&A success, and Gartner also predicts that by 2027 more than half of CDAOs will secure funding for data literacy and AI literacy programs.
The shift is from “self-service BI training” to role-based decision literacy: executives (decision framing), managers (trade-offs and drivers), analysts/engineers (semantics + quality), stewards (policy + provenance), and frontline users (safe actioning with guardrails).
Three forces converge here:
- Agents raise the bar from interpreting charts to judging automated recommendations People must recognize when to accept, challenge, escalate, or require human review—based on freshness, coverage, confidence, and policy signals.
- Trust becomes a user competency, not a platform feature Even perfect governance fails if users can’t read transparency labels or understand what “allowed-to-answer” implies in practice.
- Role-based literacy becomes the scaling mechanism for governance When thousands of users can safely self-serve with guardrails, governance stops being a bottleneck and becomes a multiplier.
Business impact: higher adoption with fewer errors, faster decision cycles, fewer “AI confidence incidents,” and lower governance friction because users understand how to operate within constraints.
CXO CTAs:
- Make literacy measurable: define role-based competencies and track completion + practical proficiency.
- Train for decisions, not features: teach how to interpret confidence, detect semantic ambiguity, and escalate safely.
- Institutionalize transparency literacy: every user should understand freshness/coverage/confidence/owner and allowed-use signals.
- Embed learning into the operating rhythm: onboarding, quarterly refresh, and incident-driven learning loops.
Trend #24: Chief Data Officer Role Evolution — From Data Steward to AI Operating Model Owner
From 2026 through 2028, the CDO/CDAO role will stop being measured by “governance coverage” and start being measured by one thing: trusted decision velocity. As copilots and agents move into business workflows, CDAOs are increasingly being handed responsibility for the AI strategy and operating model, not just the data platform. Gartner’s 2025 survey explicitly reflects this shift, noting that 70% of CDAOs have primary responsibility for building the AI strategy and operating model.
The shift is from managing data assets to running an AI-and-data value system: portfolio prioritization, decision-grade trust controls, operating rhythms, and measurable business impact. Gartner also flags the pressure point here: a major CDAO challenge is measuring data/analytics/AI impact on business outcomes, which forces the role to become outcome-led, not activity-led.
Three forces converge here:
- AI becomes an enterprise operating model change, not a tech rollout The CDO becomes the orchestrator of how data, context, policies, and tools come together safely inside workflows—because “AI value” is mostly operational, not experimental.
- Trust becomes a runtime responsibility Policy-as-code, auditability, and non-human identity/tool permissions become core CDO concerns—because the business risk is now decision risk, at machine speed.
- The role becomes portfolio + product-led Data products, semantic authority, and value measurement become the currency of influence; the CDO evolves into a GM-like leader for the decision layer.
A practical Microsoft example
In Microsoft-centric enterprises, the CDO/CDAO’s evolution typically aligns with Gartner’s stated priorities: own the AI strategy and operating model, prove measurable business impact, and scale trusted data foundations. Practically, that can look like domains shipping governed data products and certified semantics in Fabric while Purview standardizes classification and audit expectations, and Copilot/agent usage is treated as part of the measurable, auditable “decision system”—so the CDAO can run a single cadence that links value proof (outcomes and metrics), operating model execution (who owns what, how work ships), and trust at scale (governance and controls that actually hold up)
Business impact: clearer accountability for AI outcomes, faster scaling with fewer trust incidents, stronger board confidence, and fewer “pilot factories” that never convert to durable business change.
CXO CTAs:
- Rewrite the CDO charter around decisions: specify the decisions/flows the CDO owns, and the trust + outcome KPIs attached.
- Make impact measurement non-optional: cost-per-outcome, time-to-decision, rework avoided, and incident reduction by domain.
- Institutionalize the AI operating model: portfolio governance, release gates (trust + audit), and domain accountability as standard rhythm.
- Build the leadership bench: data product owners, reliability engineers, ontology/context engineers, and agent supervisors as durable roles.
Far-Fetch but Plausible Trend to Watch
Edge Trend: “Verified Decision Trails” — Cryptographically Verifiable Answers and Actions
In 3–5 years, a subset of regulated enterprises will move from “we have logs” to cryptographically verifiable decision trails: tamper-evident evidence that ties an AI answer (and any resulting action) to the exact inputs, policies, model/version, and approvals used at the time—so disputes become provable, not arguable.
Why it feels unrealistic today: most organizations still struggle to get consistent lineage, basic audit coverage, and clean identity/tool permissioning. Adding cryptographic attestations sounds like overhead.
Early signals to watch: tighter AI regulation and litigation pressure; auditors asking for stronger integrity guarantees than “log retention”; platform support for immutable/tamper-evident logging; and increased use of confidential compute and attestation patterns to prove runtime integrity.
CXO prompt: If a high-stakes decision is challenged in court or by a regulator, can you prove what happened end-to-end—or only “reconstruct” it?
One Trend That May Slow Progress
Counter-Force: Trust Debt — The Gap Between AI Pace and Enterprise Data Reality
The biggest drag on 2026–2028 progress will be trust debt: fragmented definitions, inconsistent lineage, shadow data, weak ownership, and governance that isn’t enforceable at runtime. AI accelerates exposure of these gaps because it consumes broadly and answers confidently—turning long-standing data problems into immediate decision risks.
Why it slows value: organizations respond by adding manual reviews and approvals, which restores safety but kills speed. Or they bypass governance to keep moving, which restores speed but kills trust. Either path stalls scale.
What leaders must do: invest in the “boring” foundations (semantic authority, data contracts, observability, programmable trust, and lifecycle controls) so AI can run fast without becoming a risk multiplier.
Closing Perspective — All-Up CTA
From 2026–2028, the winners won’t be the enterprises with the most AI pilots. They’ll be the ones that can repeatedly ship trusted decisions: consistent semantics, governed context, enforceable policy, auditable answers, and supervised actions—at scale.
What leaders must stop doing:
- Treating governance as documentation and exceptions as “someone else’s problem.”
- Copying data by default and hoping security and lineage catch up.
- Measuring success by artifacts shipped (reports, pipelines, copilots) instead of decisions improved.
What leaders must commit to in the next 12 months:
- Stand up a trust spine: programmable policies, auditability, non-human identity controls, and lineage that reaches answers and actions.
- Convert priority domains into decision-grade data products with contracts, SLOs, and clear owners.
- Operationalize DataOps + ValueOps: reliability discipline and cost-per-outcome economics for top workflows.
What must be re-architected (not optimized): Your context plane and trust plane. If agents are the new interface, then context assembly + trust enforcement is the new core platform—not a side project.
Enterprise-level CTA: Pick your top 10 decision flows where AI can create material impact. For each, define the allowed actions, the authoritative semantics, the trust controls, and the audit trail—then industrialize them as products. That is how AI ambition becomes trusted decisions.
Leave a Reply