The New Definition of Done for AI Agents: Moving Beyond Traditional Software Assumptions

Why Traditional Software Delivery Assumptions No Longer Hold
For decades, engineering teams have operated under a reliable assumption: if software works today, it’ll work tomorrow. Agile frameworks encoded that confidence into a “Definition of Done” (DoD)—a checklist that signaled when an increment was shippable: tests are green, security checks pass, documentation is complete, and deployment is ready.
AI agents break that assumption.
Whether you’re deploying a support agent, a coding copilot, or a multi-step workflow agent powered by LLMs, you’re shipping probabilistic and increasingly autonomous systems. Their outputs can vary. Their behavior can shift as prompts evolve, tools change, policies are updated, or models are upgraded. And their failure modes aren’t just bugs—they can become trust, safety, compliance, cost, and reputational incidents.
So the question is no longer: “Did the tests pass?” It’s: “Can we trust what this agent will do—repeatedly, safely, and under real-world conditions?”
Why the Classic Definition of Done Fails AI Agents
Traditional DoD criteria assume deterministic behavior. Agents interpret intent, decide what to do next, and often act through tools and workflows. That introduces failure modes traditional QA was never designed to catch:
- Hallucinations: confident but incorrect responses
- Drift: behavior changes as prompts, models, or tools evolve
- Prompt injection & tool manipulation: adversarial inputs trigger unsafe actions
- Data leakage: sensitive content exposed through outputs or logs
- Runaway spend & latency: loops, excessive tool calls, inefficient plans
- Bias & uneven outcomes: inconsistent quality or harmful responses across user groups
- Operational fragility: tool failures, rate limits, upstream outages, context truncation
These aren’t theoretical. OWASP has documented LLM-specific risks, and NIST’s AI Risk Management Framework emphasizes lifecycle governance over one-time testing.
Bottom line: Classic DoD validates functionality. Agent DoD must validate trustworthiness over time.
The Four Non-Negotiables in a Modern AI Agent DoD
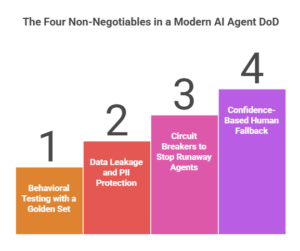
1) Behavioral Testing with a Golden Set (and explicit thresholds)
Unit tests alone won’t tell you how an agent behaves. You need repeatable behavioral regression.
Create a Golden Set—a curated suite of representative prompts and scenarios with expected outcomes. It should cover:
- primary journeys and edge cases
- tool selection and tool execution behaviors
- safe refusal scenarios (where “no” is the right answer)
- ambiguous prompts (where clarifying questions are required)
Run these evaluations continuously. If performance drops below the agreed threshold, the release is blocked.
DoD Clause: Agent meets defined thresholds on the golden set across task success, safe refusal correctness, and bounded response variance for priority use cases.
2) Data Leakage Protection and PII Handling (inputs, outputs, and logs)
Agents routinely handle customer data, internal content, and regulated information. Data protection must be built into the agent’s runtime—not bolted on afterward.
Required controls include:
- PII/sensitive entity detection and redaction in prompts and outputs
- strict logging hygiene (no raw PII, secrets, or sensitive payloads in traces)
- tenant isolation and access controls for retrieval
- synthetic leakage tests that attempt exfiltration and verify containment
DoD Clause: Sensitive data is detected and protected; logs and traces are sanitized; leakage tests demonstrate non-exfiltration under realistic adversarial attempts.
3) Circuit Breakers to Stop Runaway Agents (time, steps, spend, and safety)
Agents don’t naturally recognize when they’re stuck. Without guardrails, they can loop, over-call tools, spike latency, and burn budget.
Implement guardrails such as:
- maximum steps per task
- tool-call quotas and retry budgets
- timeouts and rate limits
- per-session spend ceilings and automated cutoffs
- kill switches for unsafe behaviors
DoD Clause: Execution enforces caps on steps, time, and spend; runaway behavior is automatically contained; unsafe trajectories trigger termination or escalation.
4) Confidence-Based Fallback and Human Escalation (don’t guess under uncertainty)
Trust collapses when agents bluff. When uncertainty is high or risk is elevated, the agent should escalate or safely refuse.
In practice, “confidence” can be determined using signals like:
- lack of grounding (no reliable sources or retrieval evidence)
- verifier checks failing (consistency or policy verification)
- high-risk intent (financial, medical, legal, sensitive workflows)
- tool execution uncertainty or repeated failures
DoD Clause: Low-confidence or high-risk scenarios trigger safe fallback, clarifying questions, or human escalation; uncertainty is communicated clearly.
Five Advanced Controls for Enterprise-Grade Agent Readiness
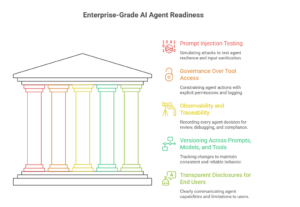
1) Prompt Injection and Adversarial Testing (including tool abuse)
Test with adversarial prompts designed to override policy, extract sensitive data, or force unsafe tool actions. Validate that tool calls are constrained by policy.
DoD Clause: Agent passes adversarial testing; tool execution is policy-bound; unsafe tool paths are blocked and auditable.
2) Governance Over Tool Access (least privilege and approvals)
Agents that can act—send emails, modify tickets, deploy code, or change data—must operate under strict permissions.
Enterprise-ready governance includes:
- least-privilege tool scopes
- time-bound and task-bound credentials
- approvals for high-impact actions
- segregation of duties and audit trails
DoD Clause: Agents operate under least privilege; sensitive actions require approval or higher assurance; all tool access is logged and reviewable.
3) Observability and Traceability (without creating new privacy risk)
You can’t govern what you can’t see. But observability must be designed responsibly.
Capture structured traces that enable debugging and compliance:
- inputs/outputs (redacted), tool calls, and results
- safety filter events and policy decisions
- evaluation scores and failure categories
- escalation outcomes and user feedback signals
DoD Clause: End-to-end traces and outcome metrics are captured with redaction, retention limits, and role-based access; investigations are feasible within defined SLAs.
4) Versioning Across Prompts, Models, Tools, and Policies (with rollback)
Small changes can create large regressions. Treat prompts, models, tools, and safety policies as versioned artifacts.
DoD Clause: Prompts/models/tools/policies are versioned; regressions are attributable; canary releases and rollback plans exist and are tested.
5) Transparent Disclosures and User Redress
When agents are user-facing, clarity is a trust multiplier. Users should know what the agent can do, where it may be uncertain, and how to escalate.
DoD Clause: User experience clearly discloses capabilities and limits; escalation and redress paths exist; issue reporting and remediation SLAs are defined.
Responsible AI: Make Accountability a Shipping Requirement
Responsible AI becomes real when ownership, governance, and remediation are operational.
Include in DoD:
- RACI: who owns safety, model changes, incidents, and compliance
- risk assessments for high-impact use cases
- documented policies for prohibited content and unsafe actions
- incident playbooks and post-mortems tied to improvements
DoD Clause: Accountability, risk assessment, and incident response are defined, exercised, and measurable—not aspirational.
Bias and Fairness: Measure Parity, Not Intent
Bias in agents often shows up as uneven service quality—tone, helpfulness, refusal patterns, or escalation likelihood—across demographics, geographies, and languages.
Practical fairness testing includes:
- cohort-based evaluation sets (language, region, persona, accessibility needs)
- parity checks for: task success, safe refusal correctness, escalation rates
- monitoring disparities in production and triggering re-evaluation when drift is detected
DoD Clause: Fairness tests show no material performance disparity across defined cohorts; monitoring alerts on emerging gaps; mitigation steps are documented.
Continuous Evaluation: Your New QA Happens Every Day
For agentic systems, “done” is not a point-in-time event. It’s a lifecycle discipline.
Minimum continuous metrics include:
- task success rate and time-to-resolution
- safe refusal correctness (the agent says “no” when it should)
- hallucination proxies (groundedness/attribution rate)
- tool-call success and recovery rate
- escalation rate and escalation correctness
- latency percentiles and cost-per-successful-outcome
DoD Clause: Evaluation runs continuously with defined SLOs; releases are gated by the same metrics used in production monitoring
Resilience: Design for Failure and Degrade Safely
Agents rely on models, retrieval systems, tools, identity, and networks—each of which can fail.
Resilience means:
- graceful degradation (read-only mode, reduced toolset, safe fallback)
- idempotent tool calls and safe retries
- chaos testing for outages, rate limits, and degraded dependency performance
- blast-radius controls: canary, throttling, feature flags, kill switches
DoD Clause: Agent meets resilience SLOs; dependency failures degrade safely; rollback and kill-switch procedures are tested and operational.
Sustainable AI: Efficiency Is a First-Class Engineering Metric
Sustainable AI is not just about values—it’s about scalability discipline and cost control.
Operationalize sustainability through:
- token budgets and context minimization
- tool-call efficiency targets
- caching and retrieval optimization
- right-sizing models based on task criticality
- tracking cost-per-successful-outcome and waste patterns
DoD Clause: Agent meets efficiency budgets per successful outcome; cost and compute waste are monitored and reduced release-over-release
What Engineering Leaders Should Prioritize This Quarter
- Redefine your Definition of Done. Include agent-specific clauses covering behavior, safety, and drift.
- Build an evaluation pipeline. Treat agent quality as a continuous metric, not a one-time checkbox.
- Harden security posture. Align with OWASP and NIST to mitigate AI-specific risks.
- Establish confidence protocols. Don’t let agents guess under uncertainty.
- Treat AI quality as a lifecycle issue. Post-launch, production monitoring becomes your new QA.
Final Thought: Shipping AI Agents Requires a Higher Bar Than “Working Code”
Teams are used to shipping when tests are green. AI agents demand something stronger: trustworthiness under change.
The real questions are:
- Will it behave safely tomorrow—not just today?
- Can we detect and contain failures before customers do?
- Can we explain what happened, trace it, and fix it quickly?
- Can we prove it’s fair, resilient, and cost-disciplined at scale?
That’s the new Definition of Done for AI agents—and it’s how you deliver agentic solutions with trust, resilience, and accountability.
Leave a Reply