Cloud Observability

Cloud based systemic optimization is central to the agility of a business in today’s post-COVID world. Whilst the accelerating trend to embrace cloud is good, the key focus should lie in identifying and outmaneuvering any future uncertainties. Nobody expected to be forced to work-from home, neither did some industries expect a volatile growth in traffic and demand. For example, Netflix saw a sharp 16 million spike in the number of new subscribers, highlighting the unprecedented growth in demand and the need for tactical systems to handle the same. With the growing scale and complexity of systems architecture and new challenges being imposed, IT professionals are under high pressure to identify anomalies, derive solutions for the same and to ensure that they don’t arise in the future. To assure that, enterprises are looking at Observability.
In this blog, I will take a closer look at “What Observability is and why it should be considered by enterprises”
What Is Cloud Observability?
Observability isn’t a new concept; it has been utilized in the world of control theory and engineering before. Observability, through the lens of control theory, can be explained as the process of measuring/understanding the internal state of a system using the externally exhibited characteristics of those systems. Observability provides the ability to explore the data exhibited by different components to answer questions about what and why something happened. More importantly, it provisions for the ability to predict the future behavior of those systems using data analysis and other technologies.
In simple words, Observability helps you to understand the complex state of your system.
One of the key ways to measure the stability of a system is through predictable outputs and feedback loops. For this to happen, the system must be observable.
By monitoring what has already happened, enterprises can reactively fix the issues. Observability, on other hand, helps predict issues before they surface, thus helping to build a proactive enterprise. Ultimately, by automating observability, it’s possible to build hyper-automated, self-healing systems that fully understand what’s happening within the systems under management, and to predict and respond to likely outcomes.
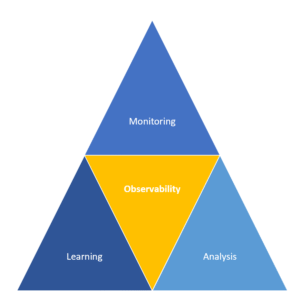
Observability Is Built on Monitoring, Analysis, and AI-Enabled Learning Systems.
How Does Observability Compare To Monitoring?

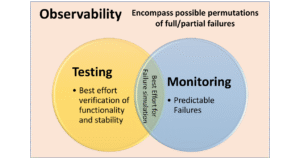
Observability is an extension of monitoring and oftentimes, they can be misunderstood as being synonymous to each other. Monitoring is more of a reactive approach whereas Observability is more of a proactive approach. Monitoring helps you to understand that something went wrong, and observability helps you to understand why it went wrong. Monitoring helps you to gauge predictable failures through predetermined metrics or logs. Whereas observability aids the monitoring process by helping you to analyze the internal state of the system and helps you to understand to attach cause to the effects, even in complex and hybrid structures. Observability, from the inference of the output, will help you to predict new problems as opposed to the symptom-oriented Monitoring approach that helps to tackle predetermined failures.
Observability and monitoring complement each other, with each one serving a different purpose. Concept of observability can be seen a superset of monitoring where it is a part of giving visibility into the system.
For example, if there’s a new dependency traced deep in the stack, observability will help you to note it whereas monitoring tools will not be able to do that. Additionally, Observability can help answer questions like:
a.) Why is ‘x’ broken?
b.) Did something change? Why?
c.) Why has the performance level decreased?
d.) What is the cause of the latency?
However, you shouldn’t compare the two as both are indispensable in maintaining the resilience of a system. Monitoring is essential to track the overall health and performance of the system and hence, you cannot substitute one for another.
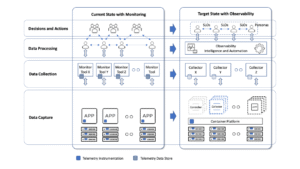
Image source: https://octo.vmware.com/cloud-observability-framework/.
Why Is Observability So Important In Multi Cloud And Hybrid Cloud Context?
As enterprises adopt microservices architecture, multiple cloud strategies and cloud native application development, it becomes even harder to assess and track all the components of an application. Within such complex contexts, one cannot monitor and know any arising anomalies. That’s where Full Stack Observability comes into picture. It helps IT professionals to understand the “unknown unknowns”, gives insight across the entire stack – from networks, to hardware’s to operating systems to even external and internal services. Essentially, it affords IT teams with the ability to help identify and solve specific hindrances and anomalies within dynamic distributed systems, without having to go from tool to tool. Modern cloud environments consist of several interconnected elements such as databases, containers, VM’s that generate data (logs, metrics and traces). Through this generated data, the teams analyse and understand where the anomalies lie.
Given that multi-cloud and hybrid-cloud span across virtual machines, containerized workloads, physical machines etc., it becomes a daunting task for IT teams to ensure availability, reliability, security, and an overall smooth performance of their applications. A detrimental task to ensure all of the above is to trace the state of the applications running in multi cloud, hybrid cloud environments and datacenters. Monitoring processes and tools, therefore, aren’t capable enough to assure resilience. Hence, observability is required.
Other Reasons Why Observability Is Important :
- Serverless and service based applications have very little visibility into their internal systems calling for the need of observability.
- Owing to the rise of automation, there is a high possibility of system failure regardless of its efficacy in ensuring reliability and lower risk. Hence, it becomes important to gather data at the granular level and IT teams must observe CI/CD and other automation tools.
- A centralized observability platform makes things easier for DevOps teams and ensures smooth and downtime-free operations. They need to have proper insight across diverse systems/infrastructures spanning from clusters to virtual machines, from servers to every cloud resource.
- Owing to the design of Kubernetes Scale, Workloads can decrease and increase based on external factors like traffic, custom policies etc. This pushes the DevOps teams to gain insight into the environment. For this, they need visibility spanning across tens and thousands of containers, which is afforded by observability.
How To Make a System Observable?
In a cloud computing system, telemetry data is generated through three formats that can be analyzed to enhance observability. These three formats include: Metrics, Event Logs and Traces.
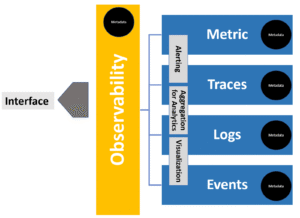
- Metrics: Metrics are numerical representations of data that are often calculated over a period (for example number of failed requests). These value counts are essentially derived from a system’s performance and can arise from various sources such as – hosts, services, cloud platforms etc. Metrics additionally, carry information about Service Like Indicators (SLI’s) that shed light on the memory and power usage. These are efficient and reliable as they’re frequently generated.
- Event Logs: Logs are structured, plain or binary texts that are computer-generated. These are time stamped records that provide accurate understanding of discrete events happening at a specific time. Event logs are insightful to gauge unpredictable behavior emerging from components of a distributed system.
- Traces – Traces provide a record for a request or transaction activity as it flows through an application. These are critical as they provide context for the previously mentioned data. For example, Traces help provide insightful information as to which metric is more important or which log is more relevant.
Three Components Of Observability
Observability, as explained earlier, provides insightful information through actionable data to answer causes of errors and anomalies. To achieve observability, these three core components are important:
- Open instrumentation: Open instrumentation entails the collection of logs from any source, be it application, service, cloud service, mobile application etc. It helps bring observability to all diverse environments and enables visibility to the entire infrastructure.
- Connected Data: It is not enough to just collect data emerging from all sources. It is important to connect it with other metadata so the sources producing these data can be identified and connected. This component gives context to the collected data from which you can derive meaningful information.
- Programmability: This component connects all of the data to the outcomes of the business. The outcomes like customer experience could be gauged and visible through KPI’s in the dashboard usually.
However, to fully see observability in relation to business outcomes, one should build curated applications on observability platforms to deliver a more interactive experience.
Options To Implement Observability In Azure
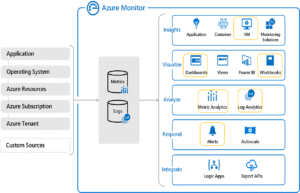
There are many tools and platforms offering for monitoring & observability, but the most robust one is Microsoft Azure Monitor – a monitoring platform that renders fullstack observability across various infrastructures and applications. You can use Azure Monitor to observe and monitor applications whether they’re hosted on premises or on Azure. Similarly, you can also utilize Azure Monitor as a single platform to manage and enhance the performance of various infrastructures like VM, Linux, AKS etc. You can additionally, use Azure Network, to monitor network issues and tackle routing issues easily as well.

Benefits Of Observability Platforms
With an open, connected, and programmable observability platform, you can:
a.) Reduce cost
b.) Enhance Resilience
c.) Accelerate for better innovation
d.) Less labor-intensive work
Continuous observability lets you stay ahead of uncertainties and risks throughout the software development cycle. Building this continuously observable system, affords you with visibility spanning across all infrastructures and the CI/CD line. This ensures speedy feedback on the status and health of your various complex environments at any given time.
Note: Watch out this space. In an upcoming blog, I will cover evaluation criteria for Observability platforms including TCO of Observability stack, filtering noise from telemetry and deep dive into top 3 Observability platforms.
Summary
As software innovation and evolution heads in uncertain directions at a volatile rate, it requires you to work in complex environments. Any innovative leap cannot be predicted and hence, you must be able to adopt and embrace these new developments without hindering the user-end experience. Hence, you require an observability platform that prepares you for any future developments and/or challenges. It should help you to reduce complexities and handle risks. Furthermore, it should be simple to adapt to for your IT teams and should enhance their understanding capabilities by displaying all the telemetry data in a single place. They must be able to gather meaningful and contextual information through these data to tackle and resolve any anomalies or errors.
2021 is entering into the era wherein observability is becoming a detrimental factor in deciding the success of a modern enterprise. 91% of IT leaders are of the opinion that. Observability must be included in their operations. Observability enhances the culture of your business organization by allowing you to garner deeper understanding of your customers, data, and systems by gaining real-time analytics.
This lets you focus on the main goal here – increased business outcomes and less time troubleshooting.
Leave a Reply