Agent Evaluation Comes to Microsoft Copilot Studio

Enterprise AI has entered its accountability era — where performance must be proven, not presumed. Microsoft’s new Agent Evaluation (Public Preview) in Copilot Studio marks that shift, transforming copilots from experiments into governed, measurable, and continuously improving systems.
Official Microsoft announcement
What’s New
- Reusable evaluation sets — import, auto-generate, or reuse chat sessions.
- Flexible review methods — semantic, lexical, intent, completeness, or abstention.
- Real-time analytics — accuracy, groundedness, and explainability built into Copilot Studio.
It brings design, testing, and governance into a single motion: build → test → optimize → trust.
Nine Pillars of Enterprise AI Agent Trust
Each pillar represents a discipline of responsible scale. Together, they create the architecture of confidence — linking governance, ethics, and operational performance.
1. Correctness — “Truth as a Baseline”
Factual accuracy aligned with domain and regulatory standards.
- Healthcare: Diagnostic summaries match current clinical protocols.
- FinTech: Financial outputs reconcile with verified accounting data. Target: ≥ 97 % accuracy; domain validation coverage > 95 %.
2. Groundedness — “Answer with Source, Always”
Every response must trace back to an approved or auditable data source.
- Healthcare: Draws from certified EHR systems or peer-reviewed studies.
- FinTech: References licensed filings or official rate sheets. Target: Grounded response score ≥ 95 %; citation reuse ≥ 90 %.
3. Compliance — “Operate Within the Rules”
Agents must follow enterprise and regulatory frameworks — GDPR, HIPAA, SOX, AML/KYC, and the EU AI Act.
- Healthcare: HIPAA-compliant data processing and consent.
- FinTech: Adherence to AML/KYC, SEC disclosure, and fairness codes. Target: ≥ 98 % policy conformance; < 1 % exception rate.
4. Audit & Traceability — “From Data to Decision”
Creates a complete chain of evidence from data ingestion to human review.
- Microsoft Purview provides the base: lineage, classification, and access logs.
- Complemented by: • Copilot Studio telemetry (prompt/response and model version). • Azure ML metadata (training lineage, evaluation records). • HITL review logs (human decisions and overrides). Outcome: End-to-end transparency that answers who, what, when, and why.
5. Safety — “Prevent, Don’t Patch”
Detects and blocks harmful, biased, or hallucinatory outputs.
- Dynamic filters and red-team tests simulate real-world misuse.
- Automatic rollback on high-risk or non-compliant responses. Target: ≥ 99 % safety index; bias-detection latency < 200 ms.
6. Experience — “Human-Centered by Design”
Focuses on tone, clarity, and responsiveness to maintain trust.
- Healthcare: Reduces clinician documentation time without losing precision.
- FinTech: Delivers clear, regulatory-ready communication. Target: ≥ 85 CSAT; < 2 s latency.
7. Autonomy Boundaries — “Know When to Stop”
Defines the limits of agent autonomy and escalation triggers.
- Sensitive decisions require human sign-off.
- Role-based controls prevent cross-domain execution. Target: Boundary-violation rate < 0.1 %; 100 % escalation logging.
8. Reasoning & Workflow — “Explain the Journey”
Captures and audits intermediate reasoning and orchestration logic.
- Provides step-by-step traceability for internal or regulatory review. Target: ≥ 95 % reasoning trace completeness; > 98 % workflow reproducibility.
9. Human-in-the-Loop (HITL) — “Judgment by Design”
Builds explicit human oversight into the decision cycle.
- Agents pause or request approval for high-risk scenarios.
- Feedback loops feed retraining and bias correction. Target: ≥ 5 % HITL engagement for critical cases; review closure < 24 h.
Five Proof Points for Trustworthy & ESG-Efficient AI
Metrics turn these pillars into measurable outcomes — ESG-adjusted metrics make them sustainable.
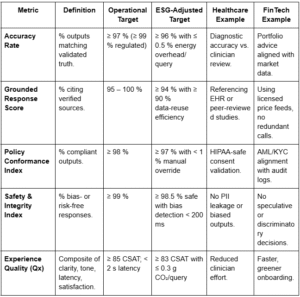
These proof points tie trust to impact — making Responsible AI measurable, auditable, and sustainable.
Why It Matters
The hardest part of AI adoption isn’t capability — it’s credibility. Agent Evaluation replaces assumption with evidence:
- Clear metrics for accuracy and compliance.
- ESG-linked efficiency reporting.
- Feedback loops that strengthen both performance and ethics.
Proof earns permission. Measured trust earns momentum.
What’s Next
- Versioned regression testing and drift analytics.
- CI/CD quality gates embedded in release cycles.
- Bias + ESG dashboards tracking trust and sustainability.
- Expanded HITL frameworks connecting human judgment to retraining.
Copilot Studio is evolving into a true Agentic Platform — where every model, workflow, and decision is observable, explainable, and efficient by design.
Executive Summary
Agent Evaluation isn’t just another capability — it’s the trust fabric of enterprise AI. It validates correctness, compliance, and conscience — embedding human judgment and sustainability into every workflow.
Define your pillars. Measure your proof points. Publish your ESG-adjusted results. Let auditability + HITL oversight anchor your next phase of trusted growth.
Leave a Reply