Rethinking AI in Data Ingestion: It’s Not About LLMs — It’s About Reducing Uncertainty

AI Didn’t Replace the Data Ingestion PM — It Changed What “Good” Means
When people talk about AI reshaping technology roles, the conversation usually centers on automation, copilots, or generative assistants rewriting how work gets done. But in foundational engineering domains like data ingestion, the transformation has been far less dramatic—and far more meaningful.
AI didn’t replace the job. It raised the bar for what quality and reliability look like.
In ingestion-heavy environments, the biggest gains haven’t come from language models. They’ve come from systems that quietly reduce ambiguity, prevent avoidable failures, and make pipelines more self-aware: detecting drift, spotting anomalies, tracking lineage, and improving observability before humans get paged.
In ingestion, the best AI doesn’t speak. It makes uncertainty visible—and manageable.
1) Invisible AI: The Real Engine of Modern Ingestion
Ingestion platforms operate in messy territory. Inputs rarely arrive clean or consistent. Data shows up in unpredictable formats, evolving structures, inconsistent naming conventions, and shifting producer behaviors.
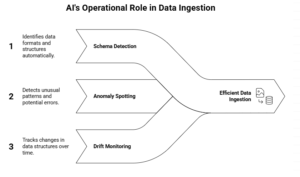
Modern systems constantly need to decide:
- What format am I looking at?
- Has the structure changed since the last batch?
- Are these records valid—or do they signal drift?
- Is the pipeline healthy, or quietly degrading?
- Is the meaning of the data changing even if the schema doesn’t?
Capabilities like schema detection, drift monitoring, anomaly detection, and confidence scoring represent AI in its most operational form: pattern recognition and decision-making under uncertainty—not language generation.
It’s not flashy. But it prevents hours of manual debugging and pipeline firefighting.
2) Why Ingestion Failures Are Usually Interpretation Failures
Most ingestion breakdowns aren’t caused by poor UI design. They happen when the system interprets the data differently than the user expects:
- A date field becomes a string
- Numeric values get mixed with text
- Encoding changes without warning
- A schema evolves silently between batches
- Null rates spike or uniqueness collapses without immediate errors
These issues stem from semantic misunderstanding, not user incompetence. Producers change behavior; consumers maintain assumptions; the pipeline tries to reconcile both—and fails in the gaps.
Solving this requires systems that recognize variability and context, rather than rigidly parsing inputs based on outdated assumptions.
3) Data Quality Starts at the Gate, Not the Warehouse
Teams often treat data quality as something to fix “downstream.” That’s how data debt forms: quality problems become normalized, copied, and amplified across systems.
At ingestion, “parseable” is not the same as “usable.” Strong ingestion systems track quality dimensions from the first mile:
- Freshness: late arrivals, missing batches, event-time lag
- Completeness: null spikes, missing partitions, dropped keys/entities
- Validity: range checks, regex/format checks, referential assumptions
- Consistency: encoding/unit shifts, enum instability, dedupe anomalies
- Uniqueness & distribution: duplicate surges, cardinality collapse, quantile drift
This is where AI earns its keep: quality checks become adaptive baselines, not brittle thresholds—detecting subtle degradations before they show up as business incidents.
4) Schema Intelligence: A Practical Expression of AI
Few features illustrate practical AI in ingestion better than schema inference done well.
Effective schema intelligence doesn’t rely on a single guess. It analyzes representative samples, estimates confidence, identifies outliers, and flags potential inconsistencies. It surfaces where the system’s interpretation is uncertain—and guides users toward safer corrections.
Good schema inference behaves like a cautious engineer:
- it samples smartly (not just the first N rows)
- it detects mixed types and low-confidence columns
- it flags outliers and suspicious value patterns
- it highlights volatility (columns that frequently change)
- it explains its confidence (“62% likely timestamp; 38% string”)
This strengthens trust because it replaces “mystery failures” with explainable behavior.
5) Auto-Detecting Schema Change Isn’t Enough—You Need Confidence + Response
Auto-detection for schema change is now table stakes. The differentiator is whether the system can distinguish between:
- Additive changes (often safe, still requires version awareness)
- Breaking changes (type changes, removed fields, widened enums)
- Semantic changes (same schema, different meaning—most dangerous)
And more importantly, how it responds:
- Accept + version when risk is low
- Quarantine suspicious partitions when confidence is medium
- Fail fast with an explainable diff when risk is high
This is how ingestion becomes resilient: not by “never failing,” but by failing early, safely, and transparently when uncertainty spikes.
6) Anomaly Detection: The Earliest Signal That Trust is Eroding
Anomaly detection in ingestion isn’t just “find weird rows.” It’s early warning across the data and the pipeline.
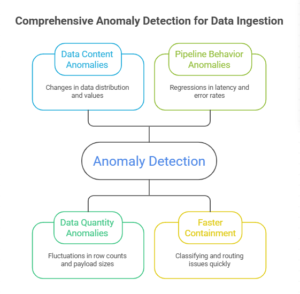
Strong systems detect anomalies in three categories:
Data content anomalies
- distribution/quantile shifts
- new or vanished categorical values
- sudden outlier spikes
- unexpected sparsity or null patterns
Data quantity anomalies (value + volume signals)
- row-count drops/spikes by partition/entity
- payload size shifts
- event-rate changes in streaming pipelines
- distinct key counts collapsing (cardinality drift)
Pipeline behavior anomalies
- latency regressions
- retry storms
- rising quarantine/error rates
- increasing SLO/SLA violations
The goal is not more alerts. It’s faster containment: classify likely causes (producer change vs pipeline regression vs seasonality) and route issues with the right severity.
7) Data Value Pattern Change: When the Pipeline Is Green but the Data Is Wrong
Some of the most expensive failures don’t break ingestion—they break meaning.
The pipeline runs. The jobs succeed. But the dataset becomes unreliable because the behavior of the data shifts:
- row counts look normal, but key entities vanish
- columns remain present, but distributions drift significantly
- uniqueness collapses, duplicates surge
- category entropy drops (values become suspiciously uniform)
This is why ingestion needs data value pattern metrics, not just schema checks:
- row counts by partition/entity
- distinct key counts, entropy, sparsity
- top-K category movement and disappearance
- null-rate and uniqueness trend lines
AI helps detect these shifts early—often before a human consumer knows what to look for.
8) Lineage Turns Incidents Into Containment (Not Chaos)
When ingestion goes wrong, the operational question isn’t just “what broke?” It’s:
- What downstream assets are affected?
- Which dashboards, reports, or models are now untrustworthy?
- Which data versions were impacted, and since when?
That requires lineage. Without it, teams either under-communicate (“probably fine”) or over-communicate (“everything may be wrong”)—both of which erode trust.
Modern ingestion needs lineage that is:
- automatically captured (not manually curated)
- granular (job → dataset → column where possible)
- time-aware (what changed when)
- connected to quality signals (impact analysis)
Lineage is how drift detection becomes targeted, confident containment.
9) Pipeline Observability: Intelligence Needs Instrumentation
Some teams attempt to layer generative explanations on top of weak foundations—using language models to narrate problems instead of investing in observability and validation.
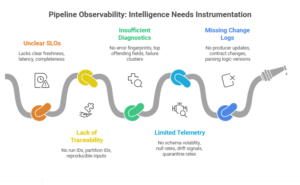
But ingestion success still depends on deterministic behavior, transparency, and guardrails. Observability is what makes intelligence trustworthy:
- clear SLOs (freshness, latency, completeness)
- traceability (run IDs, partition IDs, reproducible inputs)
- diagnostics (error fingerprints, top offending fields, failure clusters)
- telemetry (schema volatility, null rates, drift signals, quarantine rates)
- change logs (producer updates, contract changes, parsing logic versions)
Don’t ask AI to explain what you didn’t measure.
10) Autonomous Data Correction Rules: Fix What’s Safe, Quarantine What’s Uncertain
Autocorrection is tempting—and risky. Done poorly, it keeps pipelines green by silently corrupting data.
The safe approach is bounded autonomy through rules and confidence:
- Tier 1 (safe): trimming whitespace, normalizing encoding, standardizing known date formats
- Tier 2 (confidence-based): type coercion only above thresholds, always logged
- Tier 3 (unsafe): quarantine + human review for ambiguous transformations
All corrections must be:
- audited (what changed, why, confidence)
- reversible (replayability, versioned outputs)
- scoped (blast-radius awareness)
- explainable (no silent mutation)
This is uncertainty reduction in action: correct what’s provably safe, isolate what’s uncertain, and fail early when risk is high.
11) Emerging Trend: Data Copy Is Becoming a Hidden Cost Center
One emerging trend that’s easy to underestimate is Data Copy—the explosion of duplicated datasets across ingestion, staging, transformation retries, QA sandboxes, analytics replicas, and ML pipelines.
Even when storage is “cheap,” data copy creates:
- governance sprawl (which copy is authoritative?)
- higher breach surface area
- inconsistent quality rules across copies
- lineage confusion
- cost creep via redundant compute and data movement
The next frontier of ingestion intelligence is measuring and managing this: where replication happens, which consumers truly need it, and where versioned views/snapshots can replace duplication.
Common Pitfalls in AI-Driven Ingestion
- LLM-as-a-patch thinking Using a chatbot to explain failures instead of improving validation, observability, and deterministic controls. It feels helpful; it doesn’t prevent recurrence.
- Aggressive auto-correction without reversibility Fixing data silently to keep jobs green reduces alerts but increases long-term corruption risk.
- Treating schema change as episodic Schema volatility is a lifecycle reality. Without contracts, confidence scoring, and impact-aware controls, drift becomes normal—and trust erodes.
Final Thought: The Quietest AI Often Matters Most
Not every system needs a conversational interface. But every ingestion platform benefits from intelligence that reduces uncertainty, highlights risk early, and prevents avoidable failures.
In ingestion, the AI that delivers the most value is rarely visible. It doesn’t speak. It makes pipelines behave predictably in the face of messy reality—through schema intelligence, anomaly detection, lineage, observability, and bounded correction.
And that quiet intelligence may be the difference between data platforms teams trust— and data debt they never planned for.
Leave a Reply